IndexFiguresTables |
Hanseul Cho , Baekrok Shin , Chaewon Moon , Sang-Geun Hong , U-Ju Byoun , Jin-Yong Sung and Chulhee YunDeep Model-Based Optimization of Jamming Effectiveness under Aircraft AESA Radar Operational EnvironmentsAbstract: We propose a deep learning algorithm to find effective jamming parameters in the aircraft AESA radar operational environment, based on a model-based optimization technique called RoMA. To represent a series of measurements obtained under the operational environment as a single number, we design jamming effectiveness by combining ranging failure rate and average range error. Next, we collect a jamming effectiveness dataset for various radar/jammer parameter combinations by repeatedly running the simulation. Our algorithm consists of two stages: the first is to pre-train a neural network that robustly approximates the function from radar/jammer parameters to jamming effectiveness; the second is to estimate the optimal jamming parameters by exploiting our model. As a result, the proposed method improved jamming effectiveness by an average of 41.2% and up to 80.3% compared to random search, and consistently outperformed other baseline models. Keywords: AESA Radar , Jamming Effectiveness , Modeling and Simulation , Model-Based Optimization , Neural Network Ⅰ. 서 론레이다(Radar: radio detection and ranging)는 전자파의 반사를 활용해 표적의 변위와 속도 등을 알아내는 장치로, 항공기가 관여하는 전자전에서 특히 중요하다. 최근 반도체, 저전압 전원 공급 장치, transmit/receive 모듈 기술 등의 발전 덕분에 여러 고도화된 레이다가 개발되고 있다. 특히, 빔 패턴, 중심 주파수, 대역폭, 펄스(pulse) 반복 주기, 펄스 내 변조 방식 등 전자파 빔(beam)의 여러 특성을 실시간으로 바꾸어 처리하는 능동전자주사배열(AESA: active electronically scanned array) 방식의 레이다가 주목받고 있다. 표적을 효과적으로 추적하기 위해, 추적한 표적 거리가 짧아짐에 따라 AESA 레이다의 공대공(air-to-air) 운용 모드를 NAST(nose aspect search & track), AAST (all aspect search & track), ACM (air combat mode) 등으로 나누어 각 모드마다 탐지(detection) 및 추적(track) 빔을 다양하게 변경하는 기법 또한 연구되어 있다[1,2]. 레이다의 표적 탐지·추적에 대응해 아군의 생존 가능성을 높일 수 있는 전파 방해(jamming, 이하 재밍) 기법도 연구되고 있다[1,3-5]. 그러나 복잡한 양상의 전자파를 활용해 복합적으로 운용되는 AESA 레이다는 단순한 방식으로 재밍하기가 어렵다. 본 연구에서는 이를 대응하기 위한 신규 재밍 기법인 wide-open 재밍에 집중한다. Wide-open 재밍 기법은 입력된 레이다 신호를 바탕으로 멀티패스 신호와 잡음 형태를 생성함으로써 레이다 수신기의 신호 처리 과정을 통한 재밍 신호의 감쇠를 막는 기법이며, 이 특징 덕분에 (레이다) 신호 크기 대비 재밍 신호 크기의 비율(JSR: jamming-to-signal ratio)을 특히 높일 수 있다. 재밍이 효과적으로 이루어지려면 전파 교란 장치(jammer, 이하 재머)에 적용할 매개변수(parameter, 이하 파라미터) 값을 적절히 설정해야 한다. 이는 대개 전자전 전문가의 경험적 판단에 의존하는데, 실전 경험을 쌓는 것은 위험 부담이 크고 어려워 경험이 풍부한 전문가는 한정되어 있고, 따라서 그 규모를 키우기 어렵다. 한편, 레이다와 재머의 조우 상황을 모의하는 실험 장치(modeling and simulation equipment, 이하 M&S)를 만들어 효과적인 재머 파라미터가 무엇인지 미리 시험해 볼 수는 있다. 그러나, M&S의 시행마다 수십 분에서 수 시간 가량 소요되므로 가능한 많은 재머 파라미터의 조합을 시도하려면 막대한 시간이 필요하다는 문제가 있다. 위에 언급한 여러 문제들을 해결하고자 심층학습 기법 중 하나인 강화학습에 기반해 재머를 효과적으로 조종하는 방법론이 최근 다수의 연구에서 응용되고 있다[6-17]. 이 많은 기존 연구에서는 주로 레이다와 재머가 실시간으로 상호작용해 재머의 운용 모드를 실시간으로 바꿀 수 있는 적응형 운용 환경에 집중한다. 이 경우 표적의 물리량이나 재머가 수신하는 레이다의 신호 등을 현재 상태(state), 재머의 운용 방식 변화를 행동(action), 그리고 그에 따라 해당 시점에 발생하는 레이다의 측정 오류나 JSR 등의 단일 값을 보상(reward)으로 해 강화학습 모델을 훈련시킬 수 있다. 가치 기반 강화학습 기법인 Q-learning[7,17]과 Deep Q-Network(DQN)[6,10], 정책 기반의 Advantage Actor Critic (A2C)[16]과 Proximal Policy Optimization (PPO)[8], 그리고 다중 에이전트 강화학습[9,15] 등 여러 강화학습 기법이 응용되었다. 그러나, 본 논문에서는 레이다-재머 조우 상황의 시작부터 끝까지 처음에 설정한 레이다 및 재머의 파라미터 조합은 바꿀 수 없는 상황을 상정한다. 따라서, 단일 시점에 대응되는 값만을 보상으로 매길 수 없고, 대신 조우 상황을 전반적으로 고려해 재밍의 효과를 평가해야 한다. 이에 따라 기존의 연구와 달리 강화학습 방법론을 적용할 수 없으며 파라미터 조합으로부터 재밍 효과도 사이의 함수는 훨씬 복잡해진다. 게다가, 본 연구에서 다루는 wide-open 재밍 기법은 기존의 많은 연구에서 탐구한 잡음 재밍(noise jamming) 기법이나 기만 재밍(deceptive jamming) 기법과는 다른 새로운 재밍 기법임도 주목할 만하다. 본 논문에서는 심층 신경망(deep neural network)을 대용 모델(surrogate model)로 사용하는 모델 기반 최적화(model-based optimization) 기법을 활용해 AESA 레이다 운용 환경하에서 효과도 높은 재머 파라미터를 탐색하는 방법을 제안한다. M&S의 반복 시행으로 얻은 데이터 세트로 신경망을 학습해 레이다와 재머의 파라미터 값의 조합으로부터 재밍 효과도(jamming effectiveness)를 추정하는 대용 모델을 만들고, 이를 활용해 새롭게 주어지는 레이다 파라미터에 대해서도 재밍 효과도를 극대화하는 wide-open 재머 파라미터를 추정한다. Ⅱ. 데이터 세트 구축효과적인 재머 파라미터 조합을 탐색할 때 활용할 심층 신경망을 훈련시키려면 적당한 데이터 세트(dataset)가 필요하다. 이를 위해 레이다 및 재머 파라미터 조합을 다양하게 바꿔가며 M&S를 여러 번 시행하고, 각 시행마다 재밍의 성능을 수치화한 ‘재밍 효과도’를 산출한다. 최종적으로는 레이다 파라미터 조합, 재머 파라미터 조합, 그리고 재밍 효과도의 쌍들로 이루어진 데이터 세트를 확보한다. 2.1 레이다-재머 조우 시뮬레이션 설계 및 구동재머를 탑재한 표적이 정지한 레이다를 향해 고속으로 등속운동해 접근하는 공대공 AESA 레이다 운용 및 재머 구동 시나리오를 가정한다. 이를 반영한 M&S는 레이다와 재머 파라미터 조합의 쌍을 하나 입력하면 해당 레이다와 재머의 공대공 조우 상황을 모의한 시뮬레이션 결과를 출력한다. 시뮬레이션의 1회 시행 동안 레이다의 측정 시도가 특정 간격으로 여러 차례 이루어지며, 각 측정 시점마다 표적의 유무를 판단하는 탐지(detection)와 탐지된 표적의 운동에 관한 물리량을 추정하는 추적(track)을 수행한다. 이 측정 결과들을 모아 출력되는 시뮬레이션 결과에는 시행 시작부터 끝까지 각 측정 시점마다의 탐지·추적 성공 여부와 탐지·추적·실제 표적 위치를 담은 배열이 포함된다. 이때, 탐지나 추적의 성공 여부는 단지 레이다가 표적의 존재를 찾아내지 못했을 때뿐만 아니라 찾더라도 거리 오차가 500m 이상 발생하는 경우에도 성공하지 못한 것으로 간주한다[1]. 이제 M&S에 여러 레이다 및 재머 파라미터 조합 쌍을 입력해 다량의 시뮬레이션 결과를 얻는다. 우선, 정상 작동하는 레이다 파라미터 조합의 후보를 얻기 위해 재머를 구동하지 않고 오직 레이다만 운용하는 시나리오의 M&S를 수차례 시행한다. AESA 레이다 운용에 필요한 파라미터 중 표 1에 제시된 총 58가지 요소를 위주로 조정했으며, 각각을 적당한 범위에서 골라 총 1,000가지의 레이다 파라미터 조합을 만들었다. M&S에 넣어 시행한 결과, 이 중 928가지의 레이다 파라미터 조합이 재밍이 없는 시나리오에서 탐지 및 추적 성공률이 100%인 정상 작동하는 파라미터 조합임을 확인했다. 이 중 232가지의 레이다 파라미터 조합을 무작위로 선택하여 데이터 세트 구축에 사용하였다. 표(Table) 1. AESA 레이다 파라미터(자세한 범위는 보안상의 이유로 생략함) (Adjustable parameters of an AESA radar.(Details omitted for security reasons))
이후 wide-open 재밍을 포함해 구동하는 시나리오의 M&S를 수차례 시행한다. Wide-open 재밍의 조정 가능한 파라미터에는 표 2에 제시된 총 6가지가 있다. BW는 재밍 잡음 대역폭, ts1은 신호 저장 시간 길이, td0는 재밍 신호 출력 시작 시간, td1는 재밍 신호 출력 중지 시간, tr0는 재밍 반복 주기, 그리고 WO_repeat_Num은 재밍 유지 횟수를 나타낸다. 단, 표의 비고(Note) 행에 있는 설명은 아래 식 (1)을 바탕으로 레이다의 모든 운용 단계에 있는 PW나 ducy 값을 고려한다.
표(Table) 2. Wide-open 재머 파라미터(자세한 범위는 보안상의 이유로 생략함) (Adjustable parameters of a wide-open jammer. (Details omitted for security reasons))
각 레이다 파라미터 조합마다 재머 파라미터를 달리할 때 성능 변화를 측정하기 위해, 앞에서 뽑은 정상 작동 레이다 파라미터 조합 하나당 여러 가지의 재머 파라미터 조합을 무작위로 추출한다. M&S에 넣어 시행한 결과, 총 10,849가지의 레이다 및 재머 파라미터 조합 쌍에 대한 시뮬레이션 결과를 얻었으며, 각 레이다 별로 최소 30쌍, 최대 200쌍의 파라미터 조합에 대한 시뮬레이션 결과를 확보했다. M&S는 AMD EPYC 7763 CPU를 이용하여 한 번에 파라미터 조합 20쌍씩 병렬로 시행하였고, 각 시행 당 평균적으로 약 2시간이 소요되었다. 2.2 재밍 효과도 산출 기준 설정본 논문에서는 레이다-재머 조우 상황 M&S의 1회 시행에 따른 재밍의 성능을 ‘측정 실패율(failure rate of ranging)’과 ‘평균 거리 오차(average range error)’라는 두 가지 수치에 기반해 측정하고자 한다. 설명을 위해 M&S 시행 동안 총 M회의 측정 시도가 있었다고 하고 각 시점에 번호 [TeX:] $$t=1, \cdots, M$$을 부여하기로 한다. 측정 실패율 [TeX:] $$r_{\text {fail}}$$은 M&S의 1회 시행 동안의 전체 측정 횟수 중 레이다가 탐지와 추적 모두 실패한 횟수의 비율이다. 측정 시점 t에서 탐지와 추적의 성공 여부(1이면 성공, 0이면 실패)를 각각 [TeX:] $$D_t$$와 [TeX:] $$T_t$$로 나타낼 때, 측정 실패율은 다음과 같은 수식으로 표현된다.
평균 거리 오차 [TeX:] $$\Delta_{\mathrm{avg}}$$는 M&S의 시행 동안 탐지 또는 추적의 성공 시점에 발생한 측정 거리 오차들의 평균값이다. 각 시점 t에서 탐지와 추적 모두 성공한 경우 탐지 거리 오차 [TeX:] $$\Delta_t^{\text {Det}}$$와 추적 거리 오차 [TeX:] $$\Delta_t^{\operatorname{Tra}}$$ 중 작은 것을 취하며, 둘 중 하나만 성공한 경우 성공한 쪽의 거리 오차만을 취한다. 표적의 실제 거리를 [TeX:] $$R_t,$$ 탐지 거리를 [TeX:] $$\hat{R}_t^{\mathrm{Det}},$$ 그리고 추적 거리를 [TeX:] $$\hat{R}_t^{\mathrm{Tra}}$$라 할 때, 탐지·추적 거리 오차는 다음과 같은 식으로 계산한다.
(3)[TeX:] $$\Delta_t^{\text {Det }}=\left|\hat{R}_t^{\text {Det }}-R_t\right|, \quad \Delta_t^{\text {Tra }}=\left|\hat{R}_t^{\text {Tra }}-R_t\right| .$$또한, 평균 거리 오차에 포함될 시점 t에서의 측정 거리 오차 [TeX:] $$\Delta_t$$는 식으로 나타내면 아래와 같다.
(4)[TeX:] $$\begin{aligned} \Delta_t & = \begin{cases}\min \left\{\Delta_t^{\text {Det }}, \Delta_t^{\text {Tra }}\right\}, & \text { if }\left(D_t, T_t\right)=(1,1), \\ D_t \cdot \Delta_t^{\text {Det }}+T_t \cdot \Delta_t^{\text {Tra }}, & \text { otherwise }\end{cases} \\ & =D_t \cdot \Delta_t^{\text {Det }}+T_t \cdot \Delta_t^{\text {Tra }}-D_t T_t \cdot \max \left\{\Delta_t^{\text {Det }}, \Delta_t^{\text {Tra }}\right\} \end{aligned}$$위 식(4)의 맨 아랫줄은 그 위처럼 경우에 따라 나뉘는 식 표현을 피하고 한 줄의 식으로 표현하고자 할 때 이같이 쓸 수 있음을 나타낸 것이다. 이어서, 재밍 효과도 산출에 쓰일 평균 거리 오차 [TeX:] $$\Delta_{\mathrm{avg}}$$는 아래와 같이 계산한다. 단, 0/0=0으로 계산한다.
(5)[TeX:] $$\Delta_{\mathrm{avg}}=\frac{\sum_{i=1}^M \Delta_t}{\sum_{i=1}^M \max \left\{D_t, T_t\right\}}$$끝으로, 재밍 효과도는 측정 실패율과 평균 거리 오차를 조합해 산출한다. 이때, 측정 실패율에 평균 거리 오차보다 큰 가중치를 매긴다. 즉, 평균 거리 오차가 작아도 측정 실패율이 높으면 재밍이 더 효과적으로 이루어진 것으로 해석하되, 측정 실패율이 비슷할 때는 평균 거리 오차가 큰 결과가 더 재밍이 잘 된 것으로 해석한다. 이를 반영하기 위해, 재밍 효과도는 아래와 같이 계산한다.
(6)[TeX:] $$E_{\mathrm{Jam}}=\operatorname{round}\left(C \cdot r_{\text {fail }}\right)+\frac{\Delta_{\mathrm{avg}}}{\gamma}$$여기서 C와 γ는 적당히 큰 양수이고, round(.)는 반올림 함수이다. 본 논문에서는 C=100, γ=1,000으로 설정했다. 이렇게 하면 재밍 효과도 [TeX:] $$E_{\mathrm{Jam}}$$의 소수점 위는 측정 실패율 (%), 소수점 아래는 평균 거리 오차에 비례하는 값이 되어 두 수치 사이의 중요도 관계를 반영한다. 앞에서 얻은 시뮬레이션 결과를 위 식들을 바탕을 전처리해, 레이다 파라미터 및 재머 파라미터 조합과 재밍 효과도의 쌍 10,849개로 이루어진 데이터 세트를 확보했다. 재밍의 효과를 정량적으로 평가하는 것은 레이다 성능 평가보다 어렵다. 레이다의 성능은표적이 지닌 여러 물리량(거리, 방위각, 고각, 속도 등)의 탐지 및 추적 오차가 작을수록 효과적이라고 판단할 수 있다. 그러나 재밍은 정반대로 물리량 중 어느 것이 크고 작은지에 따라 어떤 재밍 결과가 다른 결과보다 더 효과적이라고 단언하기 쉽지 않으며, 심지어 탐지나 추적이 되지 않은 경우까지 고려해야 하므로 더욱 어렵다. 본 논문에서 다루는 wide-open 재밍은 탐지와 추적 모두 실패하도록 하는 것을 선순위 목표로 한다. 또한 탐지나 추적이 되었을 경우, 측정 거리 오차가 멀수록 재밍이 효과적이라고 판단한다. 이 외에도 측정 각도 오차 등 다른 측정값 또한 재밍이 효과적으로 이루어진 정도에 포함될 수 있으며, 다른 측정값으로 재밍 효과도를 정의해도 본 논문의 최적화 방법론을 적용하는 데에는 무관하다. 따라서 본 논문에서는 간단한 논의를 위해 측정 실패의 비율과 성공 시 거리 오차들의 평균만을 계층적으로 반영한 수치를 재밍 효과도로 정하고, 이 값을 극대화하는 재머 파라미터를 찾는 것을 목표로 한다. Ⅲ. RoMA 기반 재밍 효과도 최적화모델 기반 최적화(model-based optimization)란 한정된 데이터 세트만을 사용해 정확한 개형이 알려지지 않은 목적 함수를 근사하는 대용 모델(surrogate model)을 학습하고 이를 이용해 최적의 입력값을 추정하는 방법론을 일컫는다[18]. 모델 기반 최적화 방법론은 실시간 데이터 수집 유무에 따라 능동적 방법론과 수동적 방법론으로 나뉜다. 온라인 데이터 세트 기반의 능동적 방법론은 대용 모델을 훈련하는 동안 실시간으로 새로운 입력값에 대한 함숫값을 불러올 수 있을 때 사용 가능한 방법론이다. 하지만, 각 M&S 병렬 시행 당 대략 2시간이 소요되는 것을 고려할 때 이는 본 연구에 적합한 방법론이 아니다. 따라서, 본 연구에서는 오프라인 데이터 세트 기반의 수동적 방법론을 고려한다. 심층학습의 발전에 따라 흔히 심층 신경망으로 대용 모델을 설계하곤 하지만, 훈련 데이터 세트에 과적합된(overfitted) 신경망으로 근사한 함수 개형의 최적값은 과대평가되어 있을 가능성이 높다. 이런 문제를 해결하기 위해 고안된 수동적 방법론 중 하나인 RoMA(robust model adaptation)는 학습하지 않았더라도 특정 훈련 데이터와 비슷한 입력값이라면 신경망의 함숫값 추정치도 비슷하게 유지하는 강건성에 특화된 방법론이다[19]. RoMA는 1) 대용 모델 사전 학습과 2) 모델 적응 및 최적해 탐색의 두 단계로 작동한다. 대용 모델 사전 학습 단계에서는 목적 함수를 부드러운 개형으로 근사하는 대용 모델을 학습한다. 최적해 탐색 단계에서는 대용 모델로 근사한 함수의 최적해를 안정적으로 탐색한다. 이후 절에서는 재밍 효과도를 최적화하는 문제에 맞게 RoMA를 확장한 알고리즘에 대해 서술한다. 그림 1과 2에 알고리즘의 두 단계에 대한 의사코드가 각각 기술되어 있다. 3.1 대용 모델 사전 학습첫째 단계인 대용 모델 사전 학습 단계에서는, RoMA의 1단계와 유사하게, 고정된 데이터 세트만을 이용해 레이다 파라미터 조합 [TeX:] $$p_R$$과 재머 파라미터 조합 [TeX:] $$p_J$$에 따른 재밍 효과도 [TeX:] $$E_{\mathrm{jam}}$$을 근사하는 심층 신경망 [TeX:] $$f_\theta\left(p_R, p_J\right)$$를 학습한다. 이때 θ는 심층 신경망 내부 가중치 값들의 묶음으로, θ가 달라지면 [TeX:] $$f_\theta$$가 표현하는 함수 역시 달라진다. 첫째 단계의 목표는 주어진 데이터[TeX:] $$\left(p_R, p_J, E_{\mathrm{jam}}\right)$$에 대해 [TeX:] $$f_\theta\left(p_R, p_J\right)$$가 [TeX:] $$E_{\mathrm{jam}}$$에 근접하도록 θ를 잘 조정하되 [TeX:] $$p_R, p_J$$가 조금 달라지면 [TeX:] $$f_\theta$$의 출력값이 조금만 달라지도록 모델에 강건성을 부여하는 것이다. 대용 모델 학습을 위한 데이터 세트를 S라 하자. 이 때 학습의 안정성을 위해 데이터 세트 내의 모든 레이다 및 재머 파라미터와 재밍 효과도 값이 -1에서 1까지의 범위 안에 들어오도록 스케일 재조정 등 전처리를 했다고 가정한다. 만약 대용 모델이 훈련 데이터 세트 S를 잘 외우기만을 바란다면, 가능한 방법 중 하나는 각 데이터 [TeX:] $$\left(p_R, p_{\Gamma} E_{\mathrm{jam}}\right)$$마다 손실 함수 식인 [TeX:] $$\ell_\theta\left(p_R, p_J, E_{\mathrm{jam}}\right)=\left(f_\theta\left(p_R, p_J\right)-E_{\mathrm{jam}}\right)^2$$를 줄이는 방향으로 가중치를 학습하는 것이다. 그러나 강건한 모델을 학습하기 위해, RoMA의 1단계에서는 모델 입력값에 등방적 가우시안 노이즈(isotripic Gaussian noise)를 가하고 모델 가중치 θ에는 적대적 국소 변화량(adversarial perturbation) [TeX:] $$\Delta_\theta$$를 가한 변형된 손실 함수를 줄이고자 한다. 본 논문의 경우, 임의 추출한 가우시안 노이즈 [TeX:] $$\left(\delta_R, \delta_J\right) \sim N\left(0, \sigma^2 I\right)$$에 대해 [TeX:] $$\Delta_\theta$$는 아래 식에 따라 계산한다.
(7)[TeX:] $$\Delta_\theta=\left(\underset{\tilde{\theta} \in B_{\varepsilon}(\theta)}{\operatorname{argmax}} \sum_{\left(p_R, p_J, E_{\mathrm{ian}}\right) \in S} \mathbb{E}\left[\ell_{\tilde{\theta}}\left(p_R+\delta_R, p_J+\delta_J, E_{\mathrm{jam}}\right)\right]\right)-\theta$$이때 식 내부의 기댓값은 가우시안 노이즈의 무작위성에 대해 계산하며, [TeX:] $$B_{\varepsilon}(\theta)$$는 θ를 포함하는 작은 근방 집합(neighborhood)으로, 신경망의 창 대해 아래의 식으로 정의된다.
(8)[TeX:] $$B_{\varepsilon}(\theta)=\left\{\tilde{\theta}:\left\|\theta_i-\tilde{\theta}_i\right\|_F \leq \varepsilon\left\|\theta_i\right\|_F, \quad \forall i \in\{1, \cdots, L\}\right\}$$단, 식 (7) 내부의 최대화 문제는 닫힌 형식을 찾기 어려우므로, 의사코드(그림 1)의 3번 줄에서 언급하듯이 정사영 경사 상승법(Projected Gradient Ascent, PGA)을 이용해 근사적으로 푼다. 이를 바탕으로 사전 학습 단계의 손실 함수 L(θ)를 식으로 나타내면 다음과 같다.
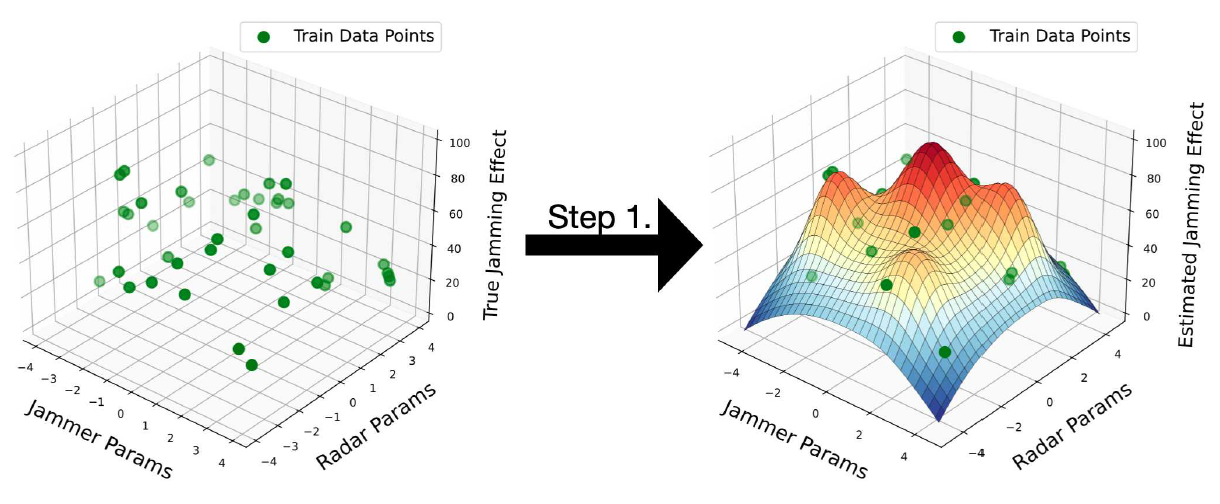
(9)[TeX:] $$L(\theta)=\sum_{\left(p_R, p_J, E_{\mathrm{sam}}\right) \in S} \mathbb{E}\left[\ell_{\theta+\Delta_\theta}\left(p_R+\delta_R, p_J+\delta_J, E_{\mathrm{jam}}\right)\right]$$위 손실 함수를 최소화하는 경사 방향으로 가중치를 갱신하는 것을 반복함으로써, 훈련 데이터 세트에 잘 맞으면서도 매끄럽고 안정적인 개형을 띠는 함수를 나타내는 모델의 가중치를 학습하게 된다. 그림 3은 대용 모델의 사전 학습 단계에 대한 개략적인 절차를 보여준다. 이 단계에서는 그림에 나타난 것처럼, 각 (레이다 파라미터, 재머 파라미터, 재밍 효과도) 쌍으로 이루어진 데이터 포인트를 기반으로(그림 3의 왼쪽), 이를 매끄러운 함수 형태로 근사할 수 있도록 대용 모델을 학습시킨다(그림 3의 오른쪽). 3.2 모델 적응 및 최적 재머 파라미터 추정치 탐색본 연구가 제시하는 알고리즘의 둘째 단계인 최적 재머 파라미터 추정치 탐색 단계에서는 앞서 학습한 대용 모델로 얻는 재밍 효과도 근사치를 최적화해 주어진 레이다 파라미터 [TeX:] $$\tilde{p}_R$$에 대한 최적의 재머 파라미터를 추정한다. 대부분 RoMA의 2단계와 비슷하지만, 본 논문의 알고리즘에는 다음과 같이 크게 두 가지 변경 사항이 있다. 우선, 대용 모델의 입력값 중 레이다 파라미터 [TeX:] $$\tilde{p}_R$$은 임의로 주어질 뿐 최적화의 대상이 아니다. 각각의 [TeX:] $$\tilde{p}_R$$마다 최적의 재머 파라미터 조합 [TeX:] $$p_J^{\star}\left(\tilde{p}_R\right) \in \underset{p_J}{\arg \max } f_\theta\left(\tilde{p}_R, p_J\right)$$를 찾는 것이 목표이기 때문이다. 따라서 대용 모델의 입력값에 대한 경사 방향을 계산할 때는 항상 레이다 파라미터를 고정한 채 재머 파라미터에 대한 경사 방향만을 계산한다. 예컨대, 의사 코드(그림 2)의 6번 줄과 같이, 대용 모델의 출력값[TeX:] $$f_\theta\left(\tilde{p}_R, p_J\right)$$을 극대화하는 방향으로 재머 파라미터 [TeX:] $$p_J$$만 갱신한다. 다만 이를 반복하다 보면 최적값을 향해 입력 값을 움직이다 훈련 데이터와 차이가 큰 입력값을 마주칠 수 있다. 이에 대한 안정성 역시 확보하기 위해 RoMA의 2단계와 마찬가지로 ‘모델 적응’ 단계를 거친다. 이는 매 입력값 갱신 직전에 아래 식 (10), (11), (12)에 따라 모델 가중치도 갱신함으로써 이루어진다. 단, 식 (12)의 최소화 문제는 닫힌 형식을 찾기 어려우므로, 정사영 경사 하강법(Projected Gradient Descent, PGD)을 이용해 근사적으로 푼다.
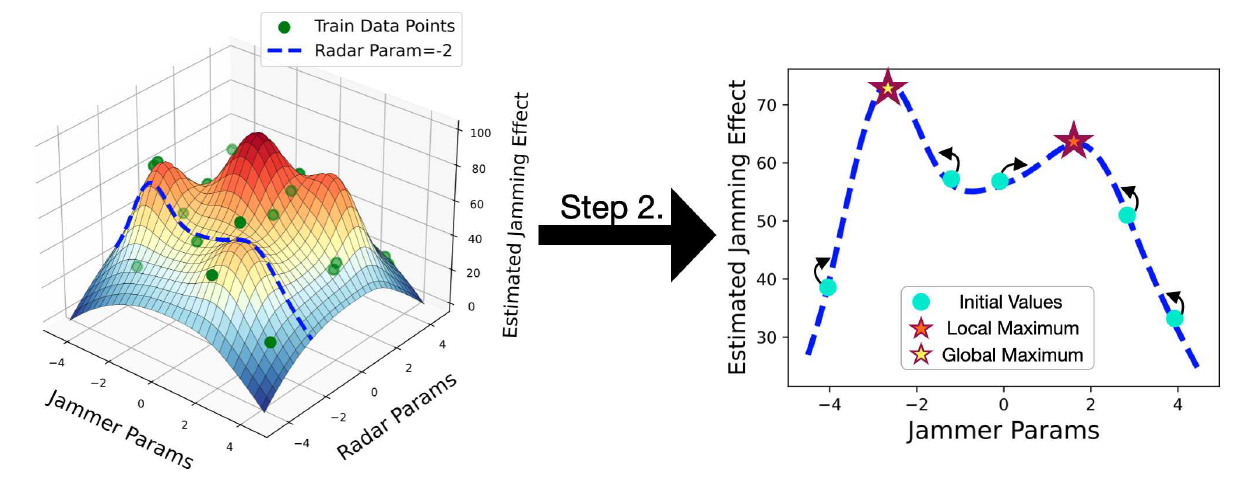
(10)[TeX:] $$g\left(\theta ; \bar{p}_J\right)=\left.\left\|\nabla_p f_\theta\left(\tilde{p}_R, p\right)\right\|_2^2\right|_{p=\bar{p}_J}$$
(11)[TeX:] $$d\left(\theta, \phi ; p_J\right)=\left(f_\theta\left(\tilde{p}_R, p_J\right)-f_\phi\left(\tilde{p}_R, p_J\right)\right)^2$$
(12)[TeX:] $$\theta_t=\underset{\tilde{\theta} \in B_{\varepsilon}\left(\theta_{t-1}\right)}{\arg \min }\left[g\left(\tilde{\theta} ; p_J^{(t-1)}\right)+\alpha \cdot d\left(\tilde{\theta}, \theta_{t-1} ; p_J^{(t-1)}\right)\right]$$여기서 [TeX:] $$\alpha \gt 0$$는 사전 학습한 대용 모델 가중치 θ가 과하게 변하는 것을 막기 위한 정규화 초매개변수이다. 위 식 (10)에서도 재머 파라미터에 대한 경사만을 계산하고 있음을 확인할 수 있다. 이처럼 입력값을 부분적으로 갱신하는 것은 입력값 전체가 최적화의 대상이었던 기존 RoMA의 문제 상황과는 다르다. 이후 실험 결과로도 확인되듯이, 사전 학습된 대용 모델이 레이다 및 재머 파라미터로부터 재밍 효과도를 잘 추정하고 있다는 가정하에, 학습되지 않은 미지의 레이다 파라미터에 대해서도 최적의 재머 파라미터를 추정할 수 있다. 또 하나의 차이점은 기존 RoMA에서처럼 단순한 경사 기반 최적화 기법으로 최적 재머 파라미터를 추정하고자 하면 재머 파라미터들 사이 제약 조건(표 2)에 부합하지 않는 파라미터를 얻을 가능성이 있다는 점이다. 이런 일이 일어나지 않고 항상 타당한 재머 파라미터를 얻을 수 있도록, 의사코드(그림 2)의 6번 줄에서 대용 모델을 최대화하는 방향으로 재머 파라미터를 갱신할 때마다 제약 조건을 만족하는 영역으로 정사영하는 연산을 추가한다. 단순한 경사 기반 최적화 기법은 국소적인 극대점에서 빠져 최적점으로 가지 못할 수도 있다. 이를 미연에 방지하기 위해, 의사코드(그림 2)의 2번 줄에서처럼 초기 재머 파라미터를 여러 개 설정해 병렬적으로 최적 재머 파라미터 탐색을 수행한다. 본 모델에서는 N=128개의 무작위한 초기 재머 파라미터에서부터 해를 갱신하는 과정을 수행하였다. 그 후 최적 재머 파라미터의 후보를 결정하는 방법은 다양하지만, 본 논문에서는 간단히 의사코드(그림 2)의 마지막 줄처럼 대용 모델의 출력값이 가장 높은 탐색 결과를 내놓기로 한다 그림 4는 본 연구에서 제안하는 알고리즘의 두 번째 단계에 대한 개략적인절차를 보여준다. 대용 모델 사전 학습 단계에서 학습된 모델을 활용하여, 먼저 레이다 파라미터를 고정한 상태에서(그림 4의 왼쪽), 대용 모델의 출력값이 최대가 되도록 모델 적응 단계를 거치며 재머 파라미터를 반복적으로 갱신한다(그림 4의 오른쪽). Ⅳ. 최적화 성능 평가 및 초매개변수 조정 방안앞서 제시한 모델 기반 최적화 기법은 구축한 (레이다 파라미터, 재머 파라미터, 재밍 효과도) 쌍으로 이루어진 데이터 세트를 활용해 대용 모델을 학습하고 이를 이용해 최적의 재머 파라미터를 탐색하는 과정을 따른다. 이때, 대용 모델이 실제 M&S를 얼마나 잘 모사하고 있는지를 평가하는 성능 검증 과정이 필수적이다. 그러나 매 단계마다 M&S를 직접 실행해 대용 모델의 성능을 검증하는 것은 비용 부담이 크기 때문에, M&S의 활용을 최소화하면서도 성능을 평가할 수 있는 프레임 워크가 요구된다. 이러한 성능 평가를 통해 대용 모델의 초매개변수를 조정할 수 있으며, 이를 통해 모델에 적합한 초매개변수를 설정함으로써 대용 모델의 성능을 더욱 향상시킬 수 있다. 이를 위해 전체 데이터 세트를 훈련·검증·테스트의 세 가지 세트로 분할하고, 검증 데이터 세트를 활용해 앞서 제시한 RoMA 기반 대용 모델의 성능이 최대화되도록 각 단계별 초매개변수를 조정하는 과정을 수행한다. 4.1 데이터 세트 분할공정한 대용 모델 성능 평가를 위해, 또 이를 바탕으로 최적화 알고리즘의 초매개변수를 조정하기 위해, 데이터 세트를 훈련·검증·테스트의 세 종류로 분할한다. 훈련 데이터 세트는 대용 모델의 사전 학습에 사용한다. 검증 데이터 세트는 사전 학습 단계와 최적 재머 파라미터 탐색 단계의 계산 방식을 결정하는 초매개변수를 조정할 때 사용한다. 그리고 테스트데이터 세트는 조정을 마친 초매개변수로 결정된 알고리즘을 처음 보는 레이다 파라미터 조합에 적용하고 그 성능을 평가하기 위해 사용한다. 이제부터는 각각의 분할된 데이터 세트를 뽑는 방식을 서술한다. 우선, 테스트 데이터 세트로는 임의로 레이다 파라미터 조합 5개를 고르고 이들 각각에 대해 무작위로 200개의 재머 파라미터 조합을 고른다. 이에 따라 테스트 데이터 세트는 총 1,000개의 레이다 및 재머 파라미터 조합 쌍과 그에 따른 재밍 효과도 값을 담도록 구성했다. 다음으로는 검증 데이터 세트를 고른다. 테스트 데이터 세트와 같은 레이다 파라미터를 사용하지 않도록 한다. 검증 데이터 세트는 다시 다음처럼 두 가지로 나눌 수 있다. 1) 1단계검증 데이터 세트 [TeX:] $$S_{\mathrm{J}}$$: 사전 학습 시 사용하는 레이다 파라미터 조합과 사용하지 않는 재머 파라미터 조합으로 구성. 2) 2단계 검증 데이터 세트 [TeX:] $$S_{\mathrm{RJ}}$$: 사전 학습 시 사용하지 않는 레이다 파라미터 조합과 재머 파라미터 조합으로 구성. 이 중 [TeX:] $$S_{\mathrm{RJ}}$$는 훈련 데이터와 다른 레이다 파라미터를 함하므로, 사전 학습 단계 검증에만 쓰이는 [TeX:] $$S_{\mathrm{J}}$$와 달리, 알고리즘의 두 번째 단계인 최적 재머 파라미터 탐색 단계의 검증에도 쓰인다. 임의의 레이다 파라미터 조합을 10개 정하고 이들 각각에 대해 재머 파라미터 조합을 10개 정하고 이들 각각에 대해 재머 파라미터 조합을 무작위로 뽑아 총 1,933개의 데이터가 들어있는 [TeX:] $$S_{\mathrm{RJ}}$$를 구성했다. 테스트 데이터 세트와 [TeX:] $$S_{\mathrm{RJ}}$$에 쓰이지 않고 남은 217개의 레이다 파라미터 조합에 대해 사전 학습을 수행한다. 단, 학습에 사용하는 레이다 파라미터 조합이라도 처음 보는 재머 파라미터에 대한 대용 모델의 성능 검증이 필요하며 이를 위한 데이터 세트가 [TeX:] $$S_{\mathrm{J}}$$다. 따라서, 훈련 데이터 세트와 [TeX:] $$S_{\mathrm{J}}$$는 앞서 테스트 데이터 세트와 [TeX:] $$S_{\mathrm{RJ}}$$에 들어가지 않은 데이터들 중에 86:14의 비율로 나누어 구성한다. 훈련 데이터 세트는 총 6,832개, [TeX:] $$S_{\mathrm{J}}$$는 1,084개의 데이터로 구성했다. 이와 같이 데이터 세트를 구성함으로써, 훈련 데이터, [TeX:] $$S_{\mathrm{J}}, S_{\mathrm{RJ}},$$ 테스트 데이터의 비율이 대략 6 : 1 : 2 : 1이 되도록 하였다. 4.2 대용 모델 사전 학습 단계의 평가 방안대용 모델 사전 학습 단계에서 조정해야 할 주요 초매개변수는 다음과 같다. 정규화의 정도를 결정하는 노이즈 크기, 사전 학습 에폭 수, 대용 모델 은닉층의 차원 수, 그리고 학습률 등이 이에 해당한다. 이러한 초매개변수를 적절히 조정하기 위해 앞서 언급한 두 개의 검증 데이터 세트를 활용하는데, 이에 앞서 대용 모델의 성능 평가 기준을 명확히 정의해야 한다. 본 연구에서는 대용 모델의 성능을 평가하기 위한 지표로 스피어만 순위 상관계수(Spearman rank correlation coefficient)를 사용한다. 검증 데이터 세트에 포함된 각 샘플에 대해 대용 모델이 재밍 효과도를 예측한 후, 실제 재밍 효과도와 모델의 예측값 간의 스피어만 순위 상관계수를 계산하게 되는데, 이는 아래와 같은 과정을 따른다. 각 검증 데이터 세트의 i번째 샘플에 대해 실제 재밍 효과도를 [TeX:] $$y_i,$$ 대용 모델이 예측한 재밍 효과도를 [TeX:] $$\hat{y}_i$$라고 정의한다. 이후 전체 샘플을 기준으로 각각의 값에 대해 순위를 부여하며, 실제 값의 순위를 [TeX:] $$\operatorname{rank}\left(y_i\right),$$ 예측 값의 순위를 [TeX:] $$\operatorname{rank}\left(\hat{y}_i\right)$$로 나타낸다. 각 샘플마다 실제 값과 예측 값의 순위 차이를 [TeX:] $$d_i$$라 하면, [TeX:] $$d_i=\operatorname{rank}\left(y_i\right)-\operatorname{rank}\left(\hat{y}_i\right)$$로 계산된다. 검증 데이터 세트의 샘플 수를 n이라고 할 때, 스피어만 순위 상관계수는 다음과 같은 방식으로 계산된다.
이 과정을 두 검증 데이터 세트 각각에 대해 수행한 후, 계산된 두 개의 스피어만 순위 상관계수에 서로 다른 가중치를 적용해 가중 평균을 성능 평가 지표로 사용한다. 검증 데이터 세트 [TeX:] $$S_{\mathrm{J}}$$의 순위 상관계수를 [TeX:] $$\rho_{\mathrm{J}},$$ 검증 데이터 세트 [TeX:] $$S_{\mathrm{RJ}}$$의 순위 상관계수를 [TeX:] $$\rho_{\mathrm{RJ}}$$라 할 때, 최종 성능 평가 지표는 [TeX:] $$0.3 \times \rho_{\mathrm{J}}+0.7 \times \rho_{\mathrm{RJ}}$$로 계산한다. 이는 대용 모델이 새로운 레이다 파라미터에 대해 정확한 예측을 수행하는 것이 더 중요하기에 [TeX:] $$S_{\mathrm{RJ}}$$에 더 높은 가중치를 부여한 것이다. 이화 같은 성능 평가 기준을 통해 대용 모델의 초매개변수를 조정할 수 있으며, 일반적으로 평가 기준 값이 높을수록 모델의 일반화 성능이 우수한 것으로 간주된다. 이를 위해 본 연구에서는 베이지안 최적화 기법에 기반한 Optuna 라이브러리[20]를 활용해 성능 평가 기준 값을 최대화 하는 방향으로 초매개변수를 탐색한다. Optuna를 이용해 총 100회에 걸쳐 서로 다른 초매개변수 조합으로 대용 모델을 학습시키고, 그중 가장 높은 성능 평가 기준 값을 기록한 조합을 사전 학습 단계에서의 최적 초매개변수로 정의한다. 4.3 최적 재머 파라미터 탐색 단계의 평가 방안위에서 도출한 최적의 초매개변수를 활용해 대용 모델을 사전 학습한 뒤, 이를 바탕으로 재머 파라미터 탐색 단계를 수행한다. 이 단계에서 조정해야 할 주요 초매개변수에는 해를 점차 증가시키는 과정에서 대용 모델의 정규화를 위해 가해지는 섭동의 강도를 조절하는 초매개변수, 해의 증가 속도를 조절하는 학습률, 그리고 해의 증가 횟수를 결정하는 에폭 등이 있다. 본 단계는 새로운 레이다 파라미터에 대해 최적의 재머파라미터를 탐색하는 과정이므로 [TeX:] $$S_{\mathrm{RJ}}$$만을 활용해 성능 평가를 수행한다. 이때 [TeX:] $$S_{\mathrm{RJ}}$$에 포함된 레이다 파라미터 10개에 대해 각각 최적 재머 파라미터 탐색 단계를 실행한다. 즉, 사전 학습을 통해 획득한 대용 모델을 활용해 총 열 번 재머 파라미터 탐색을 수행하게 된다. 이 과정에서 각 레이다 파라미터별로 최적의 재머 파라미터가 도출되면, 가장 이상적인 방법은 해당 재머 파라미터를 M&S에 입력해 실제 재밍 효과도를 확인하는 것이다. 이를 통해 재머 파라미터 탐색 단계가 적절히 수행되었는지 검증할 수 있으며, 필요시 이 단계의 초매개변수를 추가로 조정할 수 있는 가능성도 열리게 된다. 하지만 초매개변수를 조정하는 과정에서, 수많은 초매개변수 조합마다 M&S를 통해 실제 재밍 효과도를 확인하는 것은 시간과 비용이 많이 든다. 이에 따라, 본 연구에서는 이를 대체할 성능 평가 기준을 마련하고자 k-최근접 이웃 회귀(k-nearest neighbor regression, 이하 kNN) 알고리즘을 활용한다. kNN은 하나의 샘플이 주어졌을 때, 해당 샘플 주변의 가장 가까운 k개의 이웃 샘플을 기준으로 값을 예측하는 방식이다. 본 연구에서는 해당 알고리즘을 활용해 임의의 (레이다 파라미터, 재머 파라미터) 쌍의 샘플에 대한 실제 재밍 효과도를 예측한다. 구체적으로, 임의의 (레이다 파라미터, 재머 파라미터) 쌍의 샘플이 주어지면, 데이터 세트 내에서 같은 레이다 파라미터를 가지는 샘플 중 가장 가까운 3개의 샘플을 찾는다. 이후, 이 샘플들의 재밍 효과도를 거리 기반 가중 평균한 값을 해당 파라미터의 재밍 효과도 추정값으로 간주한다. 본 연구에서는 재머 파라미터가 6개의 파라미터 조합을 가지므로 유클리드 거리를 이용하여 가장 가까운 이웃 샘플을 선택하였다. 위 kNN 기반 재밍 효과도 추정값을 이용해 재머 파라미터 탐색 단계에서 사용할 최적의 초매개변수 탐색을 진행하는데, 이때 한 번 더 Optuna 라이브러리를 활용한다. 이 과정에서는 앞서 구축한 kNN 모델을 이용해 각 초매개변수 조합에 대한 성능을 검증한다. 구체적으로는, [TeX:] $$S_{\mathrm{RJ}}$$의 레이다 파라미터 각각에 대해 대용 모델의 재밍 효과도 추정치가 가장 높은 상위 5개의 재머 파라미터 값을 선택하고, 이들에 대한 kNN 기반 재밍 효과도 추정치의 평균을 계산한다. 이렇게 구해진 각 레이다 파라미터별 평균값 5개에 대해 거듭 평균을 취해 최종 성능 평가 지표로 사용한다. Optuna는 이 성능 평가 지표 값을 최대화하는 방향으로 초매개변수를 50번 탐색하며, 이를 통해 재머 파라미터 탐색 단계에서 사용할 최적의 초매개변수를 도출한다. Ⅴ. 실험 결과위 방법론으로 도출한 최선의 초매개변수와 이를 바탕으로 학습한 대용모델을 이용해, 테스트 데이터 세트에 포함되어 학습과 검증 과정에서 사용된 적이 없는 레이다 파라미터 각각에 대해 최적 재머 파라미터를 추정한다. 이 과정에서 대용 모델이 예측한 추정 재밍 효과도가 가장 높은 재머 파라미터를 해당 레이다 파라미터에 대한 최적의 재머 파라미터로 간주한다. 단, 대용 모델이 출력한 최적 재머 파라미터는 연속적인 실숫값을 가지며, 실제 M&S에 입력하기 위해서는 각 재머 파라미터가 정의된 해상도에 맞게 반올림되어야 한다. 이후, 해당재머 파라미터가 실제로도높은 재밍 효과를 가지는지를 확인하기 위해 각 (레이다 파라미터, 재머 파라미터) 조합을 M&S에 입력해 실제 재밍 효과도를 계산한다. 하지만 레이다 파라미터에 따라 재밍에 대한 민감도가 상이하기 때문에, 재밍 효과도 값 그 자체를 모델 성능의 절대적인 척도로 사용하기에는 한계가 있다. 따라서 대용 모델이 제안한 재머 파라미터의 실제 재밍 효과도를 다른 방법론과 비교함으로써 상대적인 성능을 평가할 필요가 있다. 다만, 본 연구는 조우 시 설정된 초기 파라미터가 고정되는 정적 상황을 가정한다. 이는 실시간 상호작용을 통해 재머 파라미터를 동적으로 조정하는 기존 강화 학습 기반 방법론들의 구동 환경과 근본적인 차이가 있다. 이러한 환경적 차이로 인해 강화학습 방법론은 비교군에서 제외했으며, 본 연구에서 고려하는 비교 대상은 다음과 같다. 1) 무작위 추출 기법 (Random Baseline): 무작위 선택한 재머 파라미터의 재밍 효과도의 평균 2) NN: 테스트 레이다와 가장 가까운 훈련 레이다에서 훈련 데이터 세트 내의 재머 파라미터 중 가장 높은 재밍 효과도를 가지는 값 (Nearest Neighbor, 이하 NN)을 사용했을 때의 재밍 효과도 3) FCN: RoMA 방법론을 적용하지 않고 일반적인 방식으로 훈련된 신경망(Fully Connected Network, 이하 FCN) 대용 모델에 경사 상승법을 적용하여 찾은 재머 파라미터의 재밍 효과도 이 비교군들과 RoMA 기반 대용 모델이 도출한 재머 파라미터의 성능을 비교하여 본 논문에서 제안한 방법론의 상대적 우수성을 수치적으로 평가한다. 표 3은 각 테스트 레이다에 대한 방법론 각각이 추정한 최적 재머의 재밍 효과도를 나타낸 것이다. 표 3의 마지막 열은 각 방법론의 평균 상호 순위(Mean Reciprocal Rank, 이하 MRR)이다. MRR은 순위화된 결과에서 각 항목이 평균적으로 얼마나 상위에 있는지를 평가하는 지표로, 1에 가까울수록 성능이 우수함을 의미한다. 이때 i번째 레이다에서 방법론 A의 재밍 효과도 순위를 [TeX:] $$\operatorname{rank}_i(A)$$라 하면, 방법론 A의 평균 상호 순위 MRR(A)는 다음과 같이 구할 수 있다.
표(Table) 3. 무작위 추출 기법, NN, FCN, 제안된 모델의 재밍 효과도와 평균 상호 순위 (Jamming effectiveness of Random Baseline, NN, FCN and Ours and their mean reciprocal rank (MRR).)
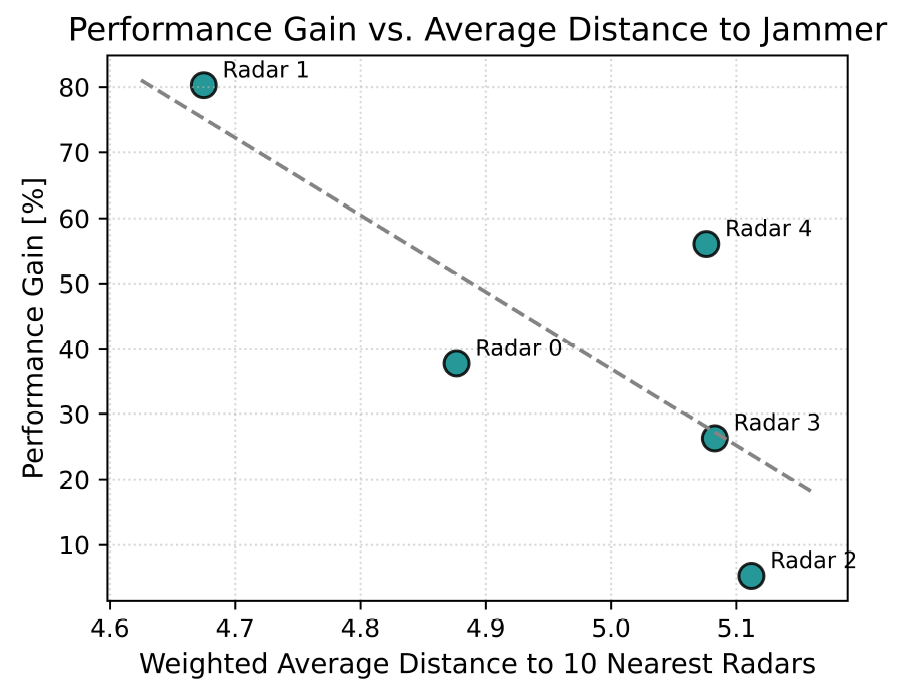
본 논문이 제안한 모델의 MRR은 0.7로, 비교군인 무작위 추출 기법(0.37), NN 방법론(0.45), FCN 방법론(0.57)보다 높은 수치를 기록했다. 이는 제안한 모델이 다양한 테스트 레이다 환경에 강건한 성능을 보인다는 것을 의미한다. 그림 5에는 테스트 데이터 세트에 포함된 5종의 레이다 파라미터에 대해, 무작위로 추출한 각 200개의 재머 파라미터들의 평균 재밍 효과도 대비 본 논문에서 제안한 모델이 추정한 재머 파라미터의 재밍 효과도가 얼마나 향상되었는지를 비율로 구하여 나타내었다. 5종의 레이다 파라미터 모두에서 성능 향상이 확인되었으며, 무작위 추출 대비 평균 41.2%의 향상 효과를 보였다. 특히, 레이다1에 대해서는 무작위 추출 대비 최대 80.3%까지 향상된 경우도 관찰되었다. 그림(Fig.) 5. 무작위 추출 기법 대비 제안한 모델의 재밍 효과도 향상률 (Percentages of improvements in jamming effectiveness of Ours over Random Baseline.) 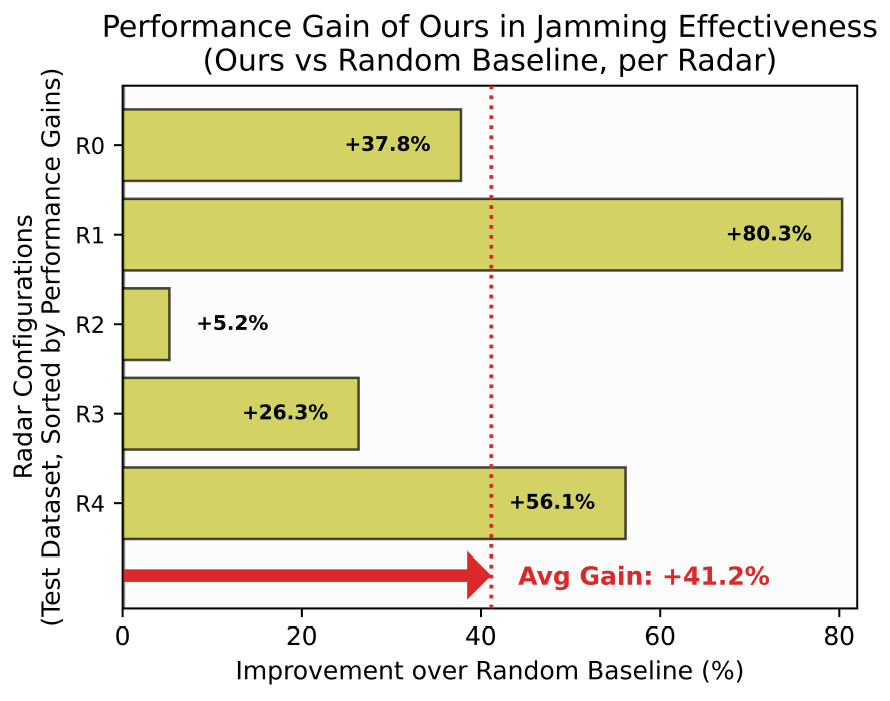 반면, RoMA 방법론을 적용하지 않은 최근접 이웃(Nearest Neighbor) 레이다의 최적 재머 파라미터를 사용하는 방법론(그림 6)과 FCN 모델(그림 7)은 평균적으로 무작위 추출보다 우수한 성능을 보이지 못했다. NN 방법론의 경우, 전체 5종의 테스트 레이다 파라미터 중 2종에서는 무작위 추출 대비 성능 향상이 있었지만, 나머지 3종에 대해서는 오히려 성능이 크게 하락하여 평균 -25.8%의 성능 향상을 보였다. FCN 방법론 역시 5종 중 3종의 테스트 레이다 파라미터에 대해 무작위 추출보다 낮은 성능을 기록했고, 평균 -17.8%의 성능 향상을 보였다. 그림(Fig.) 6. 무작위 추출 기법 대비 NN의 재밍 효과도 향상률 (Percentages of improvements in jamming effectiveness of NN over Random Baseline.) 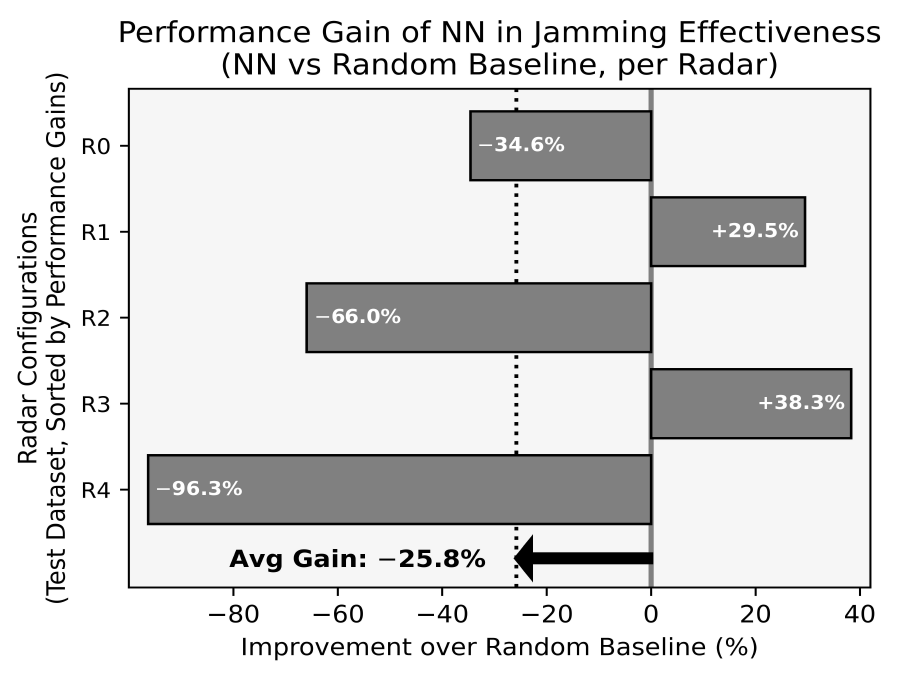 그림(Fig.) 7. 무작위 추출 기법 대비 FCN의 재밍 효과도 향상률 (Percentages of improvements in jamming effectiveness of FCN over Random Baseline.) 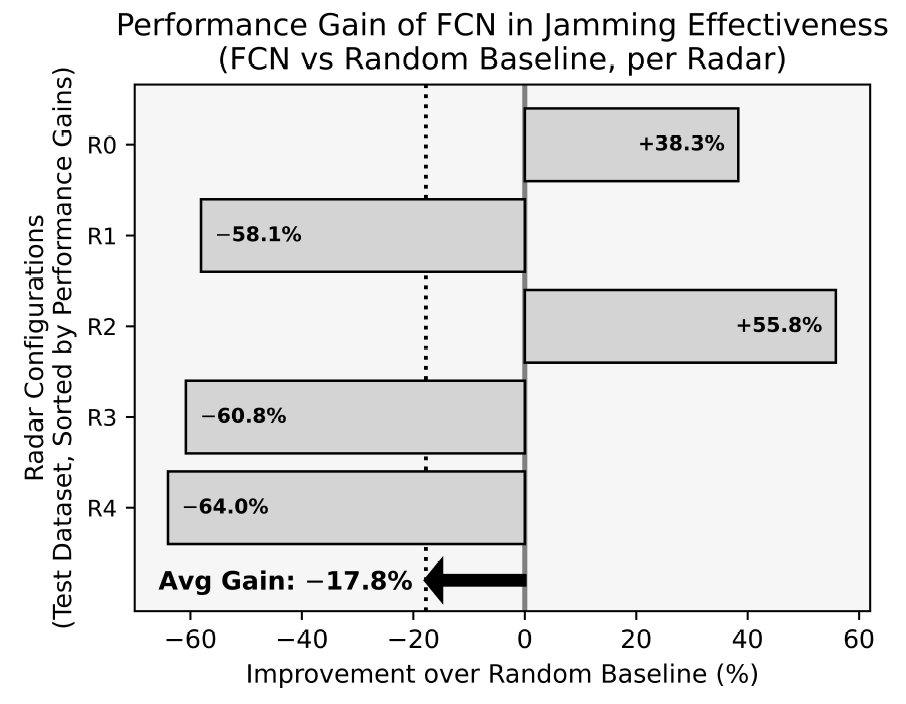 레이다에 따른 RoMA 방법론의 재밍 효과도 향상률의 차이를 이해하고자 해당 테스트 레이다가 학습 데이터에 포함된 레이다들에 대해 어느 정도의 거리를 가지고 있는지를 분석하였다. 레이다 파라미터별로 중요도에 따라 가중치를 부여하고, 전체 훈련 데이터 세트에서 해당 레이다와 거리가 가장 가까운 10개의 레이다를 찾고 이 레이다들과의 거리를 평균 내었다. 그림 8에서 볼 수 있듯이, 가장 높은 재밍 효과도 향상률을 보여준 레이다 1은 훈련 데이터 세트와 가장 가까운 레이다였고, 가장 낮은 재밍 효과도 향상률을 보여준 레이다 2는 훈련 데이터 세트와 가장 먼 레이다였다. 이때 레이다 간 거리는 레이다 파라미터별 가중치를 적용한 뒤 유클리드 거리를 이용하여 거리를 측정하였으며, 전반적으로 거리가 멀어질수록 재밍 효과도 향상률이 떨어지는 경향성이 나타났다. 이를 통해 훈련 데이터를 더 보강하여 다양한 레이다를 포함한 훈련 데이터 세트를 구성하면 여러 레이다에 대해서도 안정적인 재밍 효과도 향상률을 보일 수 있을 것이라고 기대할 수 있다. Ⅵ. 결 론본 연구에서는 항공기 AESA 레이다 운용 환경에서 효과적인 재머 파라미터를 탐색하기 위해, 심층 신경망 기반의 모델 기반 최적화 기법을 제안했다. 제안된 기법은 M&S 결과를 근사하는 신경망 기반 대용 모델을 학습한 후, 이를 활용해 모델이 처음 접하는 레이다 파라미터에 대해 재밍 효과도를 최대화하는 재머 파라미터를 탐색하는 방식으로 작동한다. 실험 결과, 학습 또는 검증 시 접하지 못한 레이다 파라미터에 대해, 본 논문이 제안한 기법이 도출한 최적 재머 파라미터는 무작위로 추출한 재머파라미터 대비 평균41.2%의 재밍 효과도 향상률을 보였으며, 다른 기준 모델들과의 비교를 통해 본 방법의 우수성을 검증하였다. 이러한 성능 향상 외에도, 제안된 기법은 실질적인 운용 관점에서 다음과 같은 활용 가능성을 제시한다. 첫째, 대용 모델이 구축된 이후에는 이전에 접하지 못한 새로운 레이다 파라미터 조건에 대한 최적 재머 파라미터 탐색이 약 3~4분 내에 신속하게 이루어질 수 있어, 변화하는 위협 환경에 빠르게 대응하는 데 기여할 수 있다. 이는 방대한 경우의 수를 모두 M&S하는 것보다 효율적인 대안이 될 수 있다. 둘째, 본 모델이 추천하는 재머 파라미터는 실제 장비에서의 성능 최적화를 위한 재머 파라미터 탐색 과정에서 효과적인 초기 시작점으로 활용될 수 있어, 시행 착오를 줄이고 파라미터 최적화 과정을 가속할 수 있을 것으로 기대된다. 본 연구는 재밍 효과도를 ‘측정 실패율’과 ‘평균 거리 오차’ 두 가지 수치만을 조합하여 정의했다. 하지만 재밍 효과도의 정의는 이에 국한되지 않으며, ‘평균 각도 오차’와 같은 지표를 통합하여 정의할 수 있다. 중요한 점은 재밍 효과도의 세부 정의가 달라지더라도, 본 연구에서 제안하는 방법론은 동일하게 적용 가능하다는 것이다. 마찬가지로, 본 연구의 방법론은 wide-open 재밍 기법에만 한정되어 있지 않으며, 더 많은 재밍 기법에 확장해 적용할 수 있다. 나아가, 비슷한 방법론으로 시간에 따라 변화하는 동적 재머 파라미터를 효과적으로 최적화하는 모델을 개발할 수 있을 것으로 기대한다. BiographyBiographyBiographyBiographyBiographyBiographyBiographyReferences
|
StatisticsCite this articleIEEE StyleH. Cho, B. Shin, C. Moon, S. Hong, U. Byoun, J. Sung, C. Yun, "Deep Model-Based Optimization of Jamming Effectiveness under Aircraft AESA Radar Operational Environments," The Journal of Korean Institute of Communications and Information Sciences, vol. 50, no. 11, pp. 1647-1659, 2025. DOI: 10.7840/kics.2025.50.11.1647.
ACM Style Hanseul Cho, Baekrok Shin, Chaewon Moon, Sang-Geun Hong, U-Ju Byoun, Jin-Yong Sung, and Chulhee Yun. 2025. Deep Model-Based Optimization of Jamming Effectiveness under Aircraft AESA Radar Operational Environments. The Journal of Korean Institute of Communications and Information Sciences, 50, 11, (2025), 1647-1659. DOI: 10.7840/kics.2025.50.11.1647.
KICS Style Hanseul Cho, Baekrok Shin, Chaewon Moon, Sang-Geun Hong, U-Ju Byoun, Jin-Yong Sung, Chulhee Yun, "Deep Model-Based Optimization of Jamming Effectiveness under Aircraft AESA Radar Operational Environments," The Journal of Korean Institute of Communications and Information Sciences, vol. 50, no. 11, pp. 1647-1659, 11. 2025. (https://doi.org/10.7840/kics.2025.50.11.1647)
|