IndexFiguresTables |
Jeongjun Park♦ and Saewoong Bahk°Resizing Method for Applying RF-based Data to ViT in Human Activity RecognitionAbstract: This paper applies RF-based data, obtained through the commonly used Radio Frequency (RF) approach in human activity recognition (HAR), to the Vision Transformer (ViT), a state-of-the-art machine learning method for image classification. Through this process, we analyze the challenges arising from applying RF-based data, which have different sizes compared to standard image dimensions, to ViT. To address these challenges, we propose various input resizing methods. Furthermore, through a comparison of these resizing methods, we identify the most effective resizing approach for RF-based data, achieving an average accuracy improvement of 9.57%. Keywords: Vision Transformer , RF-based data 박정준♦, 박세웅°인간 활동 인식에서 RF 기반 데이터를 ViT에 적용하기 위한 Resizing 방법요 약: 본 논문에서는 인간 활동 인식에서 주로 사용되는Radio Frequency (RF) 방식을 통해 얻은 RF 기반데이터를 최신 이미지 분류를 위한 머신러닝 기법인Vision Transformer (ViT)에 적용하였다. 이 과정에서이미지 크기와 다른 RF 기반 데이터의 크기를 ViT에적용할 때 발생하는 문제점을 분석하고, 이를 해결하기 위해 고려해야 할 입력 사이즈resizing 방법들을제시하였다. 또한, 다양한 resizing 방법들과의 비교를통해 RF 기반 데이터에 가장 효과적인 resizing 방식을 제안하였으며, 이를 통해 평균 9.57%의 성능 개선을 달성하였다. 키워드: Vision Transformer, RF 기반 데이터 Ⅰ. 서 론최근 인공지능 기술의 발전으로 인간 활동 인식 (Human Activity Recognition, HAR) 기술이 헬스케어, VR/AR, 감시 시스템 등 다양한 분야에서 활용되고 있 다[1-3 ]. 이러한 기술들은 주로 카메라를 활용하여 인간 의 움직임과 행동을 파악해왔으나, 이러한 데이터 수집 방식은 개인의 사생활 침해 우려를 야기하여 사용에 제 약이 따를 수 있다. 이러한 문제를 해결하기 위해 최근에는 Radio Frequency(RF) 신호를 활용한 인간 활동 인식 기술이 주목받고 있다[4]. RF 신호 기반 HAR 기술은 주로 Ultra-wideband (UWB), Frequency-Modulated ContinuousWave(FMCW), WiFi를 이용하며, 개인의 프라이버시를 보다 효과적으로 보호할 수 있다. 또한, RF 기반 데이터는 2D 이미지 형태로 변환이 가능하여, 최적화된 이미지 분류 기법(예:Convolutional Neural Networks, Vision Transformers)의 도움을 받을 수 있 다. 이러한 이유로 RF 데이터를 수집하고 이를 머신러 닝 기법으로 분류하려는 연구가 점차 증가하고 있다[5,6]. 이미지 분류를 위한 최신 머신러닝 기법 중 하나로 Vision Transformer (ViT)가 있다[7]. ViT는 주로 224×224 크기의 이미지를 입력으로 받으며, 이를 16×16 크기의 패치로 나누어 총 14×14(196)개의 패치 로 조각낸다. 각 패치는 특정 차원의 벡터(patchembed- dingvector)로 표현되며, 이 벡터는 패치의 위치 정보 를 포함한 벡터(positional embedding vector)와 결합되 어 Transformer Encoder에 입력된다. 이후 연산 과정을 통해 이미지를 분류하게 된다. 그러나 대부분의 RF 기반 데이터는 입력 크기가 224×224가 아니기 때문에 ViT에 직접 적용하기 어려 운 문제가 있다. 특히, 패치의 크기가 정사각형일 경우 데이터를 완벽하게 조각내기 어렵고, 패치의 개수가 달 라지면서 미리 학습된 positional embedding vector를 각 patch embedding vector에 적용할 수 없게 된다. 이를 해결하기 위해 본 논문에서는 RF 기반 데이터를 ViT에 적용하기 위한 새로운 resizing 방법을 제안한다. Ⅱ. 실험 방법본 실험의 목적은 RF 기반 데이터를 resizing하여 ViT에 적용하는 것이다. RF 기반 데이터는 이미지와 다른 크기를 가지며, UWB, WiFi, FMCW 등 다양한 기술로부터 얻을 수 있다. 본 실험에서는 거리 분해능이 높고 시간에 따른 펄스의 다중 경로 정보를 포함하여 2D 형태의 데이터로 변환할 수 있는 특성을 지닌 UWB 데이터를 사용한다. UWB 데이터는 이러한 특성으로 인해 최근 다양한 연구에서 활발히 활용되고 있다. UWB 데이터의 신호를 간단히 표현하면 다음과 같다.
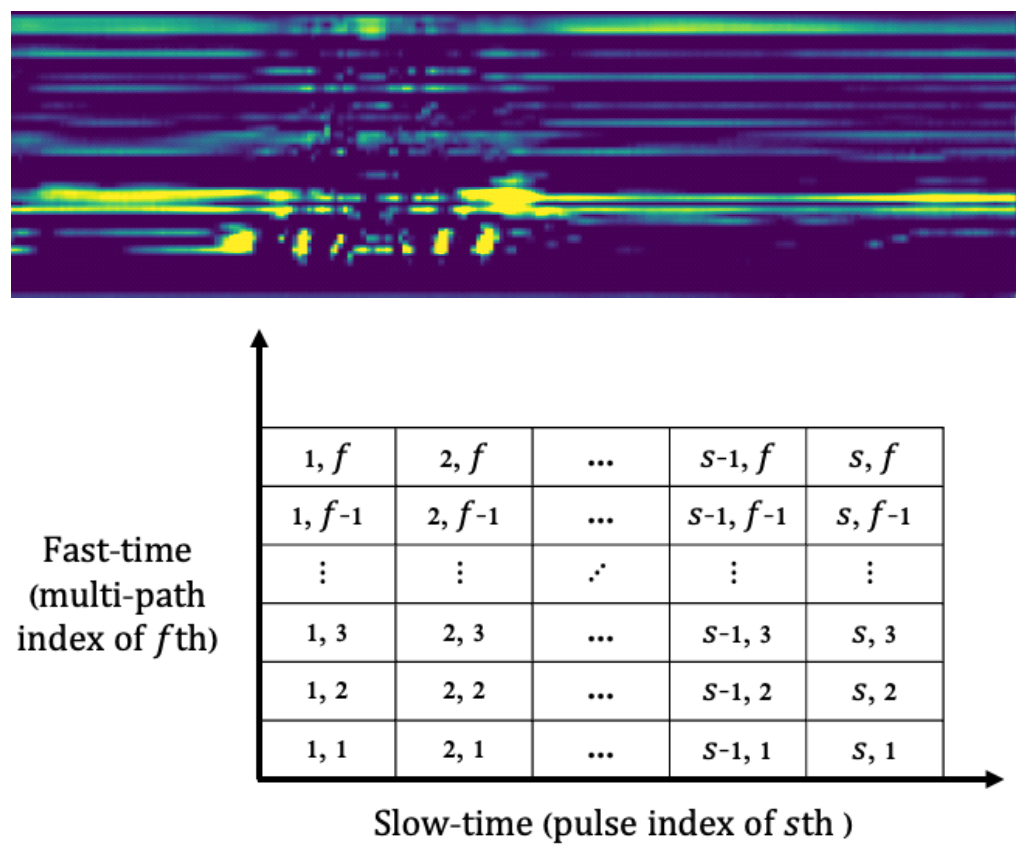
(1)[TeX:] $$\begin{equation} r_s(t)=\sum_{f=1}^F \alpha_f \delta\left(t-\tau_f\right) * m_s(t)+n_s(t) \end{equation}$$r과 m은 수신과 송신된 신호이고, s와 f는 각각 slow time (pulse index)와 fast time (다중 경로 index)를 나 타낸다. n과 α는 각각 노이즈와 감쇠 인자를 나타낸다. 수집된 UWB 데이터[8]를 이용하여 그림 1과 같이 51x500 사이즈의 데이터를 실험에 이용한다. 해당 데이 터세트는 9명으로부터 7가지의 행동을 수집한 데이터 이며 각 피실험자의 데이터로 테스트하여 classification 정확도의 평균을 구한다. Training data와 testing data 는 철저히 분리하여 training에 참여하지 않은 data를 testing에 사용하였다. 본 논문에서는 다음의 네 가지 resizing 방식을 고안 및 비교하였다: 1) simple resizing, 2) square patching, 3) rectangular patching, 4) rectangular patching with interpolation이다. Simple resizing 방법은 RF기반 데이터 사이즈에 상 관없이 이를 224 × 224로 up-sampling 또는 down-sam- pling을 적용하여 이미지 사이즈와 동일하게 변환한 후 ViT에 적용하는 방식이다. Square patching 방법은 입력 데이터의 사이즈를 변 경하지 않고, 기존의 16x16패치를 이용하해 데이터를 조각낸 뒤 ViT에 적용하는 방법이다. 이때 입력 데이터 의 사이즈가 16으로 나누어 떨어지지 않는다면 필요한 사이즈만큼 zero padding을 사용한다. Rectangular patching은 정사각형 패치 대신 입력 데 이터의 크기에 따라 직사각형 모양의 패치를 생성하여 patch embedding을 수행하는 방식이다. 본 실험에서는 51×500 크기의 데이터를 14×14개의 패치로 나누기 위 해 패치 크기를 4×36으로 설정하였다. 마지막 방법인 rectangular patching with inter- polation은 입력 데이터의 짧은 변이 224보다 작을 경우 이를 보간(interpolation)을 통해 224로 확장하고, 긴 변 은 크기를 유지한 채 패치 크기를 계산하는 방식이다. 이 방법은 긴 변의 정보를 보존하고, 짧은 변의 정보를 보간하여 이미지 크기와 유사하게 맞춤으로써 resizing 과정에서 정보 손실을 최소화한다. 이 방식에서는 16×36 크기의 패치가 적용된다. 동일한 실험 환경을 유지하기 위해 다음과 같은 실험 설정을 적용하였다. ImageNet으로 사전 학습된 ViT를 활용하여 UWB 데이터를 30 epoch 동안 파인튜닝 (fine-tuning) 하였다. Optimizer는 Adam을 사용하였 고, learning rate은 0.00001로 설정하였으며, 손실 함수 로는 cross entropy를 사용하였다. Ⅲ. 실험 결과각 방법의 성능을 평가하기 위해 정확도를 측정하였 으며, 결과는 표 1에 요약되어 있다. Table 1. 방법 별 평균 정확도
Simple resizing은 가장 간단한 방식으로, 최근 연구 에서 널리 사용되고 있다[9]. 그러나 RF 기반 데이터는 224보다 큰 사이즈를 가질 수 있기 때문에 단순히 이를 down-sampling할 경우 정보 손실이 크게 발생한다. 특 히, 입력 데이터 사이즈가 224보다 클 경우 필연적으로 정보 손실이 발생하게 된다. Square patching의 경우, 14.28%로 가장 낮은 정확 도를 보였다. 이는 입력 데이터의 사이즈에 따라 패치의 개수가 달라지기 때문이다. 패치 개수가 14×14(196개) 에 미치지 못하면 사전 학습된 positional embedding vector와의 결합이 문제를 일으키게 되고, 이로 인해 학 습이 제대로 이루어지지 않아 낮은 정확도가 나타난다. Rectangular patching은 입력 데이터 사이즈에 따라 패치 면적이 작아질 수 있다. 패치 내의 정보량이 줄어 들면 patch embedding 과정에서 충분한 정보를 제공하 지 못해 성능 저하가 발생할 수 있다. Rectangular patching with interpolation은 정보 손 실 문제가 없고, 입력 데이터 사이즈가 224보다 작더라 도 보간을 통해 데이터를 확장하여 패치 크기의 정보 손실을 보완한다. 또한, 패치 개수를 유지할 수 있어 사전 학습된 positional embedding vector의 적용에 문 제가 없다. 이러한 특성 덕분에 가장 높은 정확도인 61.77%를 기록하였다. 본 논문은 정확도의 절대적인 수치에 초점을 맞추기 보다, 현재 널리 사용되는 방법에 비해 정보 손실을 줄 이는 resizing방식을 통해 성능을 개선할 수 있음을 주 장한다. References
|
StatisticsCite this articleIEEE StyleJ. Park and S. Bahk, "Resizing Method for Applying RF-based Data to ViT in Human Activity Recognition," The Journal of Korean Institute of Communications and Information Sciences, vol. 50, no. 5, pp. 725-727, 2025. DOI: 10.7840/kics.2025.50.5.725.
ACM Style Jeongjun Park and Saewoong Bahk. 2025. Resizing Method for Applying RF-based Data to ViT in Human Activity Recognition. The Journal of Korean Institute of Communications and Information Sciences, 50, 5, (2025), 725-727. DOI: 10.7840/kics.2025.50.5.725.
KICS Style Jeongjun Park and Saewoong Bahk, "Resizing Method for Applying RF-based Data to ViT in Human Activity Recognition," The Journal of Korean Institute of Communications and Information Sciences, vol. 50, no. 5, pp. 725-727, 5. 2025. (https://doi.org/10.7840/kics.2025.50.5.725)
|