IndexFiguresTables |
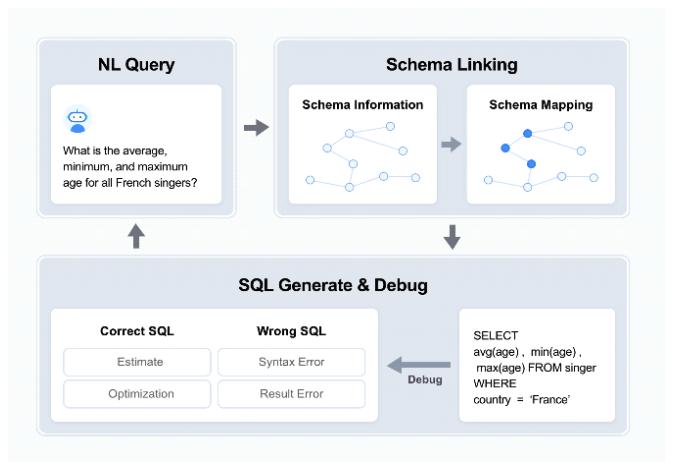
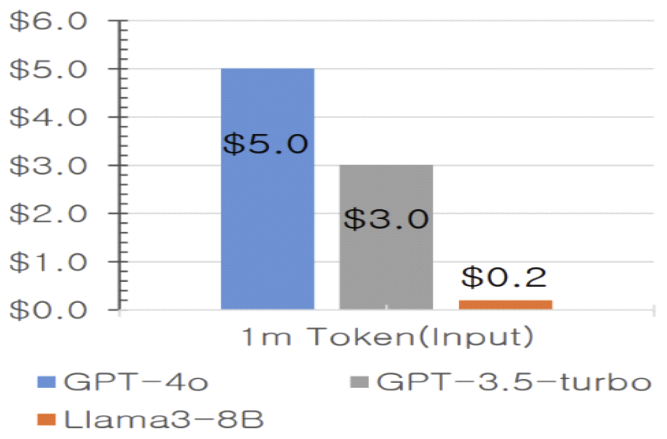
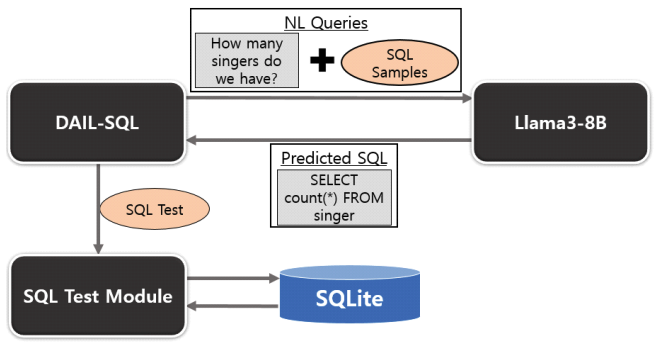
Jae-young Im♦ and Soo-Yeon Yoon°Approaches to Lightweight Text-to-SQL Implementation Based on sLLMAbstract: This study proposes a lightweight Text-to-SQL implementation based on sLLM (smaller Large Language Model) to solve the high cost and security issues of existing LLM (Large Language Model) based Text-to-SQL models. To this end, we implemented a Text-to-SQL model using DAIL-SQL[1] and Llama3-8B and evaluated its performance using Spider dataset[2]. In this study, we secure the shortcomings of the existing Few-shot Learning method and propose improvement measures such as fine-tuning, knowledge distillation, and selection of similar queries through RAG to improve the performance of sLLM-based Text-to-SQL. By resolving the security vulnerabilities of existing LLM-based Text-to-SQL and presenting an efficient way to implement sLLM-based Text-to-SQL, we expect to expand the utilization of Text-to-SQL in various industries. Keywords: sLLM , Text-to-SQL Ⅰ. IntroductionText-to-SQL is a technology that converts sentences written in natural language into SQL queries that databases can understand. It bridges the gap between users and complex databases, showing high potential in various fields such as business intelligence(BI), data analytics, and chatbot systems. In particular, it simplifies the user-database interaction by retrieving real-time data from the database, reducing the time to make business decisions and improving customer service[3]. Large Language Models (LLMs) have been a hot topic of research in the text-to-SQL space in recent years. By leveraging the language processing power of LLMs, it has become possible to generate sophisticated SQL by better understanding natural language and mapping it to schema information. However, LLM-based text-to-SQL has some fundamental limitations. The main limitation is theinability to use online LLMs for security reasons. Text-to-SQL relies on the internal database schemainformation of a company or organization, whichissensitive information that should not be leaked totheoutside world. In addition, LLMis much moreexpensive per token than sLLM, which is the main reason for the high cost of LLM-based Text-to-SQLusing the Few-Shot Learning method. Finally, domain-specific output is difficult to verifyintraditional LLM-based Text-to-SQL. Additional training is required to produce domain-specific results, and LLM requires more expensive andtime-consuming training than sLLM. Previous LLM-based text-to-SQL research has focused on improving the performance of text-to-SQL itself. However, there is a lack of research on security issues, high cost, and difficulty in domain-specific services. In this paper, we propose a lightweight Text-to-SQL model implementation based on sLLM(smaller Large Language Model). To solve the existing problems of the existing LLM-based Text-to-SQL, we designed a sLLM-based Text-to-SQL model. We prove that sLLM is a more suitable language model for Text-to-SQL than LLM, and we also propose specific measures to improve the performance of sLLM-based Text-to-SQL. Through this research, we expect to be able to design a Text-to-SQL model that is suitable for companies and institutions that are sensitive to information leakage and have specialized domains such as national defense and healthcare. Ⅱ. Related Work2.1 sLLM2.1.1 Definition of sLLMTraditional large language models (LLMs) are highly performant as they contain hundreds of billions of parameters, but they also require vast computing resources and are expensive to learn and infer. The small Large Language Model (sLLM) has emerged to overcome the limitations of LLMs. An sLLM is a small language model with about 1 billion parameters, which maintains the performance of LLMs while increasing efficiency in terms of computing resources and costs. 2.1.2 Background of sLLMThe sLLM emerged to address the shortcomings of traditional LLMs. LLMs provide high performance, but due to their size, they require a lot of resources and time during the learning and inference process. To solve this problem, sLLM is a way to reduce the size of the model and still operate efficiently. It is increasingly recognized that not only the size of the model, but also the quality of the data and specialized training are important factors in improving performance. Instead of simply throwing in large amounts of data, we show that high performance can be achieved with small models using properly processed data and optimized learning strategies. 2.1.3 Recent Technological Trends in sLLMRecently, sLLM-related techniques have evolved into a variety of methodologies to achieve model reduction while maintaining performance. First, knowledge distillation techniques have been activelystudied to efficiently compress knowledge fromlargemodels into small models[4-8]. Second, model lightweighting techniques are also widely usedtoreduce computing resources by removing unnecessary parameters or optimizing the model structure. In addition, methods such as fine-tuning have beenproposed to efficiently train small models tailored to specific domains[9-11]. 2.2 Text-to-SQL2.2.1 Definition of sLLMIn real time, important information is stored in databases. Text-to-SQL is used as a technology to effectively retrieve this important information in real time. Text-to-SQL is a technology that learns the schema structure of a database and converts queries written in natural language into SQL queries that the database can understand. This overcomes the limitation that LLM (Large Language Model) provides results based only on learned information, and allows you to directly retrieve the latest information stored in the database. 2.2.2 Development Process of Text-to-SQLThe early days of Text-to-SQL research were dominated by rule-based approaches. The first rule-based Text-to-SQL can be considered the CHILL system [12] by Zelle and Mooney. It used Inductive Logic Programming (ILP) to implement rule-basedText-to-SQL, and later evolved to generate domain-specific rules [13] to translate natural language questions into SQL. These early efforts focused on generating SQL queries using explicit rules between the database schema and natural language questions. In the early 2010s, to overcome the limitations of rule-based approaches, statistical approaches begantoreplace them. In the early 2010s, a statistical approachwas proposed[14] to automatically learn the mappingbetween database schema and natural language using data-driven models, which can be described as an important step forward as a generalized methodology that can be applied to a wide variety of database structures without being specific to a particular domain. In the late 2010s, advances in deep learning-based natural language processing led to the use of deep learning-based models in text-to-SQL[15-18], with Seq2Seq models gaining significant attention in text-to-SQL research. A representative model that utilizes Seq2Seq models is the Seq2SQL model[19]. This model proposed a method for generating SQL queries from natural language using reinforcement learning, and showed excellent performance on the WikiSQL dataset. More recently, large language models (LLMs) and transformer-based approaches have significantly improved the performance of Text-to-SQL[20-23]. Models such as RAT-SQL[24] improve Text-to-SQL performance by explicitly modeling schema-query relationships using transformers[25]. 2.2.3 LLM-based Text-to-SQLRecently, the text-to-SQL space has also seen a flurry of research based on Large Language Models (LLMs). According to the Spider[2] leaderboard, four out of the top five (as of April 12, 2024) are Text-to-SQL models based on LLMs. LLM is widely used in Text-to-SQL because it performs well in accurately understanding and processing users' natural language queries. The basic sequence of Text-to-SQL is systematically performed as shown in Fig. 1 First, there is a step to relate the natural language (NL Query) queried by the user to the schema structure of the database. This step is called Schema Linking, which matches the natural language query with the schema information of the database to identify the database elements that match the intent of the query. The next step is to generate SQL based on this schema structure. The SQL generation process reflects the meaning of the natural language query and generates a query that conforms to SQL syntax. The complex natural language representation must be properly mapped to the tables, columns, and conditions in the database. The generated SQL queries are not executed immediately, but are evaluated. The main evaluation factors are whether the query is grammatically correct and produces logically correct results. If grammatical errors or execution errors are found during the evaluation process, the SQL is debugged and fixed[26]. 2.2.4 Issues with LLM-based Text-to-SQLLLM-based Text-to-SQL has two main problems. The first is that the LLM is expensive to implement and maintain. Figure. 2 compares the price of GPT-4oand Llama3-8B APIs, you can see that GPT-4o costs 25 times more. From this cost perspective, sLLMismuch more economical than LLM. Second, if schema information is compromised, the database can be exposed to a number of serious security threats[27]. First, SQL Injection attacks can become more sophisticated. If the schema structure is compromised, an attacker can determine the internal structure of the database, including tables, columns, and so on, which can be used to target specific data. These attacks can enable illegal data manipulation, such as viewing, modifying, or deleting data. It also increases the risk of data theft. Attackers can utilize schema information to identify the tables where sensitive data is stored, and then target and attempt to steal sensitive information. In particular, such an attack can severely impact the credibility of an organization/enterprise, with the potential for legal and financial damage. Finally, you may be vulnerable to a database denial of service (DoS) attack. If schema information is leaked, an attacker can design complex, resource-intensive queries based on the structure of the database to deplete the database's resources. This can prevent the database server from functioning properly and severely degrade the availability of your application. Schema information leakage is more than just a security threat; it is a serious problem that threatens the integrity, confidentiality, and availability of the database. By changing the online-based LLM to an offline-based sLLM that prevents schema leakage and makes it inaccessible from the outside, you can effectively solve the security problem. Ⅲ. Experimental Setup3.1 DatasetFor our experiments, we used the Spider dataset, a leading benchmark dataset in the Text-to-SQL field. Spider[2] was annotated by 11 Yale University students to address the problem that existing datasets like WikiSQL contain only simple SQL queries and single tables. The dataset contains complex SQL queries with 10,181 questions and covers a wide range of SQL syntax, including multiple tables, Having, Group By, Limit, and Join. The SQL difficulty level is categorized into Easy, Medium, Hard, and Extra Hard. We collected 200 databases covering 138 domains from various sources, including university databases, DatabaseAnswers, and WikiSQL, from which Yale students wrote 20-50 questions and SQL labels for each database. 3.2 Experimental ModelIn this study, we organized the experimental model as shown in Fig. 3, the experimental model was configured as shown in Fig. Predicated SQL was created through DAIL-SQL and Llama3-8B, and actual SQL was executed through SQL Test Moduleto evaluate the performance. 3.2.1 DAIL-SQLAs a text-to-SQL model, we use DAIL-SQL[1]. DAIL-SQL is a Text-to-SQL model proposed by Dawei Gao, which is a Text-to-SQL model based on Few-shot learning implemented with the DAIL Selection method, which combines Masked Question Similarity Selection (MQS) and Query Similarity Selection (QRS). We chose DAIL-SQL as a text-to-SQL-based model in this study because it has a running accuracy of 86.6\% on the Spider dataset and has shown high adaptability and performance for various domains and complex SQL queries. Masked Question Similarity Selection (MQS) replaces table names, column names, values, etc. inquestions with mask tokens to minimize the negative impact of cross-domain information. Their embedding similarity is calculated using the k-Nearest Neighbor(kNN) algorithm to increase applicability across different domains. This allows us to effectively select the right SQL samples for few-shot learning. Query Similarity Selection (QRS) utilizes a prior model to select examples similar to the target SQL to generate initial SQL based on the target question and the database. It uses the generated initial SQL as an approximation and encodes it into a binary discrete phrase vector based on keywords in the SQL. The best examples are selected by considering their similarity to the approximated SQL and the diversity among the selected examples. In this way, DAIL-SQL can effectively perform text-to-SQL conversion in different domains and select the best SQL queries. 3.2.2 Llama3-8BIn this study, we used the Llama3-8B model released by Meta AI in April 2024 as sLLM. Llama3-8B is a model that realizes high performance with fewer parameters by introducing Grouped Query Attention (GQA) technology, which was previously applied only to large-scale models in Llama2, to small and medium-sized models. In particular, Llama3-8B outperforms Llama2 70B, and also shows superior results in terms of computational efficiency and resource utilization. The study was conducted in May 2024, shortly after the release of Llama3-8B, and these characteristics are consistent with the purpose of this study, which requires a high-performance model in a limited resource environment. 3.2.3 SQL Test ModuleTo measure the accuracy of Text-to-SQL, we used the method proposed in their study [28]. This method is a test suite-based evaluation method for evaluating the semantic accuracy of Text-to-SQL models, and since traditional string matching or single database comparison methods can lead to errors, we created a small test suite that runs queries across multiple databases to evaluate accuracy. This method is more reliable for semantic evaluation of complex queries and can effectively reduce false negative and false positive errors than traditional metrics. Ⅳ. Experiment4.1 Experimental Procedure4.1.1 Selection of Examples for Few-shot LearningMasked Question Similarity Selection (MQS) and Query Similarity Selection (QRS) techniques are used to select examples that are appropriate for the questions required for the experiment.In this course, you will learn how to select appropriate examples for Few-shot Learning to improve learning performance. 4.1.2 Querying the Llama3-8B ModelGenerate predictive SQL queries by querying the Llama3-8B model with real-world questions along with examples selected for Few-shot Learning. 4.1.3 Evaluation of SQL QueriesEvaluate the generated predictive SQL query to ensure that it works correctly. The SQL queries are executed on the real database and the results match the correct answer (Gold SQL). For example, if you ask Llama3-8B the question “How many singers dowe have?” in the Spider dataset, Llama3-8B will return SQL like “SELECT count(*) FROM singer”. This is called Prediction SQL, and we will compare Prediction SQL to Gold SQL. 4.2 Evaluation MetricsThe Spider dataset uses two evaluation metrics: Exact Match Accuracy (EM) and Execution Accuracy(EX). Each metric plays an important role in measuring the performance of the model. First, Exact Match Accuracy (EM) evaluates how well the predicted SQL query (Prediction SQL) matches the gold SQL (Gold SQL) character by character. This metric focuses on determining if the predicted SQLis structurally and syntactically identical to the correct answer. EM will only have a high value if all elements of the SQL query match exactly - keywords, tables, columns, conditional expressions, etc. This is useful for evaluating how accurately the model's predicted query embodies the correct query, and is especially important for verifying that it has accurately learned the complex syntactic structure of SQL. EM is the percentage of correctly matched queries out of all predictions, expressed as a percentage. [TeX:] $$\begin{equation}\mathrm{EM}=\frac{\text { Number of Exact Matches }}{\text { Total Number of Predictions }} * 100\end{equation}$$ Execution Accuracy (EX), on the other hand, is a metric that measures how well the results of apredicted SQL query match the results of the correct SQL when it is executed on the actual database. This metric focuses on evaluating the performance of the model based on the execution results of the SQL query. Because slightly different SQL syntax can often lead to the same result, EX is useful for determining whether the model actually performed the correct database operations. For example, in a SELECT query, there may be multiple ways to return the same query result, and EX evaluates whether these query results match the correct answer. EX is the percentage of SQL executions that matched the correct result, expressed as a percentage. [TeX:] $$\begin{equation}\mathrm{EX}=\frac{\text { Number of Correct Executions }}{\text { Total Number of Executions }} * 100\end{equation}$$ These two metrics complement each other. EM evaluates how accurately the model generated the same SQL syntax as the correct query, while EX evaluates whether the syntax actually produces the correct result. This allows you to measure both the syntactic correctness and the practical validity of your model. Because EM and EX have their own strengths and weaknesses, using both metrics together provides a more comprehensive assessment of a model's performance. 4.3 Experimental ResultsAccording to Table.1, which compares the performance with the existing LLM-based Text-to-SQL model, the DAIL-SQL +Llama3-8B model has a performance of EX 69.2, which is 82.9\% of the performance of the comparison model, DAIL-SQL + GPT-4 model. This result proves that the sLLM-based lightweight text-to-SQL design approach can solve the problems of the existing LLM-based text-to-SQL model and maintain high performance. In particular, this result is meaningful because it shows competitive performance despite adopting a lightweight structure with sLLM. Table 1. DAIL-SQL + Llama3-8B experimental results and the accuracy of existing Text-to-SQL models
4.4 Results AnalysisIn Table 1, the DAIL-SQL + Llama3-8B model performs 46.8 in Exact Match Accuracy (EM) and 69.2 in Execution Accuracy (EX). EM evaluates how well a Predicated SQL query matches Gold SQL character by character, and is a measure of the structural correctness of SQL. The result of 46.8 on EM may seem low, but this is because the nature of SQL is such that there are many different syntaxes that can produce the same result, and EM only evaluates structural matching. On the other hand, EX scored 69.2, which is about 82.9\% better than the 83.4 of EX for the comparison model, DAIL-SQL+GPT-4. This shows that the lightweight sLLM model can provide competitive performance while maintaining high cost-effectiveness and security. Also, as shown in Table 2, the accuracy of DAIL-SQL + Llama3-8B model by SQL difficulty tends to decrease gradually as the difficulty increases. At the EASY level, both EX and EM recorded a high accuracy of 85.1\%, but as the difficulty level increased to MEDIUM, HARD, and EXTRA, the performance dropped sharply to 68.2 for EX and 46.8 for EM. These results indicate that the model is struggling to handle difficult SQL queries. This is likely due to the fact that the general performance of Llama3-8B is worse than that of LLM. We found that Llama3-8B is less accurate on complex SQL compared to LLM because it uses Few-shot Learning, which is highly influenced by the general performance of the model. Table 2. Results of DAIL-SQL + Llma3-8B by SQL Difficulty Level
From the failure cases presented in Table 3, wecan see that the proposed model tends to fail in cases of high SQL complexity, especially for JOIN operations involving multiple tables. For example, the SQL queries generated by the model on HARD and EXTRA difficulty levels did not accurately capture the relationships between tables compared to the target SQL query, leading to incorrect results. This shows that the model's performance degrades significantly as the complexity of the SQL query increases. Table 3. Failure Case of DAIL-SQL + Llma3-8B
Ⅴ. Conclusion and ImplicationsIn this study, we propose an implementation of sLLM-based text-to-SQL model to compensate for the limitations of LLM, rather than focusing on performance improvement of existing LLM-based text-to-SQL research. As a result of the study, the sLLM-based model showed stable results in terms of performance compared to the existing LLMmodel, and the possibility of significantly reducing the cost of deployment and maintenance was confirmed. Inparticular, sLLM is different from LLMin that it iseasy to deploy offline and can provide domain-specific services. These features are expectedto be a major factor in selecting sLLM-based text-to-SQL models over LLM-based text-to-SQL models in companies and institutions with specialized domains and network environments that are isolated from the outside world, such as defense, healthcare, and public institutions. In this study, we found that sLLM-based Text-to-SQL models still have limitations in handling complex SQL queries. To overcome this, we propose additional performance improvement measures asfollows. First, we introduce fine-tuning techniques such as LoRA(Low-Rank Adaptation)[31] and QLoRA(Quantized LoRA)[32] to enhance the performance of sLLM. We expect these techniques to be useful in improving both efficiency and accuracy through domain-specific learning while maintaining model size. In addition, we utilize Knowledge Distillation techniques to transfer LLM's high SQL generation performance to sLLM by using LLMasa teacher model, which improves the ability to handle complex SQL while maintaining lightweight. Finally, by employing a vector database to retrieve schema elements semantically aligned with natural language queries and integrating them using the Retrieval-Augmented Generation (RAG) [33] framework, the system can better capture complex schema structures and inter-table relationships. This approach enhances query accuracy by enabling context-aware identification and mapping of relevant tables and attributes, while also improving efficiency in large-scale relational databases through automated schema retrieval. In future work, we will focus on training sLLM on additional datasets, such as BIRD[34], in addition to the Spider dataset, using the Fine-Tuning technique to precisely learn the relationships between database tables and optimize the generation of complex SQL queries. Fine-tuning is expected to further enhance the performance of sLLM-based Text-to-SQL models and greatly expand their applicability in various domains. Ultimately, the results of this research will enable domain-specific optimized SQL query generation, enabling efficient data processing in various industries. BiographySoo-Yeon Yoon2017 : Ph.D. degree in IT Policy Engineering, Soongsil University 2020~Current : Assistant Professor, School of Software, Kookmin University 2017~2020 : Adjunct Professor, Duksung Women’s University 2009~2020 : Adjunct Professor, Soongsil University [Research Interests] Large-scale AI Models, NLP, LLM/MLLM, Big Data Analysis [ORCID:0000-0002-4148-5433] References
|
StatisticsCite this articleIEEE StyleJ. Im and S. Yoon, "Approaches to Lightweight Text-to-SQL Implementation Based on sLLM," The Journal of Korean Institute of Communications and Information Sciences, vol. 50, no. 8, pp. 1183-1191, 2025. DOI: 10.7840/kics.2025.50.8.1183.
ACM Style Jae-young Im and Soo-Yeon Yoon. 2025. Approaches to Lightweight Text-to-SQL Implementation Based on sLLM. The Journal of Korean Institute of Communications and Information Sciences, 50, 8, (2025), 1183-1191. DOI: 10.7840/kics.2025.50.8.1183.
KICS Style Jae-young Im and Soo-Yeon Yoon, "Approaches to Lightweight Text-to-SQL Implementation Based on sLLM," The Journal of Korean Institute of Communications and Information Sciences, vol. 50, no. 8, pp. 1183-1191, 8. 2025. (https://doi.org/10.7840/kics.2025.50.8.1183)
|