IndexFiguresTables |
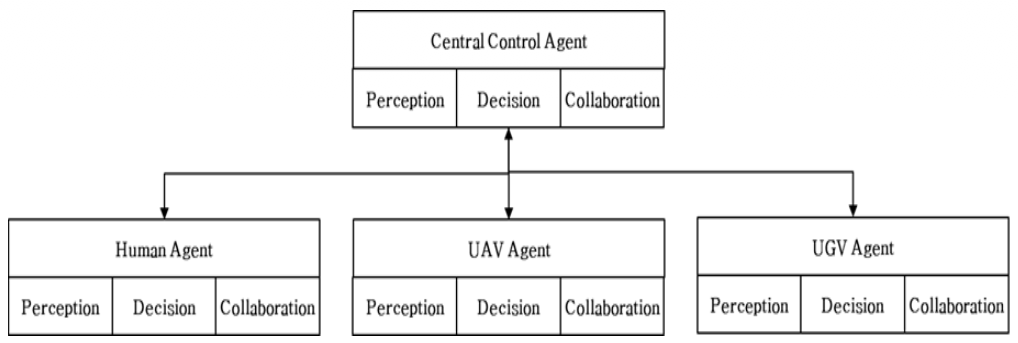
Jaekyu Cho♦°A study on AI-based dynamic intelligent mission and collaboration architecture for MUMTAbstract: Modern battlefields are evolving into multi-domain operations(MDO) encompassing land, sea, air, cyber, and space. Advances in technologies like artificial intelligence and robotics are increasing the utility of Manned-Unmanned Teaming (MUMT). However, for MUMT systems to simultaneously ensure mission efficiency and survivability under battlefield uncertainty, partial observability, and communication constraints, mission reorganization that can immediately adapt to unpredictable changes and optimized collaboration between heterogeneousplatformsareessential. This paper proposes a Dynamic Intelligent Mission and Collaboration Architecture(DIMCA), which combines real-time mission reassignment and collaboration optimization based on the Partially Observable Markov Game(POMG). Through a modular structure of perception, decision, and collaboration, DIMCA rapidly derives optimal team composition and reallocation decisions in the event of dynamic events (e.g., new mission assignments, platform damage, or communication degradation). Simulation results show that DIMCA consistently improves mission success rates compared to comparable systems(GCN, MLP). Furthermore, it proactively addresses mission failure risks through reallocation responsiveness over time, and improves resource efficiency by reducing movement and fuel consumption. Therefore, this study demonstrates its potential to accelerate the OODA(Object-Orient-Decide-Act) loop and enhance operational resilience in multi-domain battlefields. Keywords: MUMT , Command and Control , AI , Mission reassignment , Collaboration 조재규♦°유·무인 복합전투체계를 위한 AI 기반 동적 임무 재할당 및 협업 아키텍처 연구요 약: 현대 전장은 지상·해양·공중·사이버·우주를 아우르는 다영역 작전(Multi Domain Operations) 환경으로 진화되고있으며 인공지능·로봇 등의 기술 발전으로 유·무인 복합체계(MUMT, Manned Unmanned Teaming)의 활용성이증대되고 있다. 그러나, 전장에서의 불확실성·부분관측·통신 제약 하에서 유·무인 복합전투체계가 임무 효율성과생존성을 동시에 확보하려면, 예측 불가능한 변화에 즉시 적응하는 임무 재편과 이기종 플랫폼 간 협업 최적화가필수적이다. 본 논문은 POMG(Partially Observable Markov Game)를 기반으로, 실시간 임무 재할당과 협업 최적화를 결합한 DIMCA(Dynamic Intelligent Mission and Collaboration Architecture)를 제안한다. DIMCA는 인식– 결정–협업의 모듈 구조를 통해 동적 사건(새 임무 부여, 플랫폼 손상, 통신 저하 등) 발생 시 최적의 팀 조합과재할당 결정을 신속히 도출한다. 시뮬레이션 결과, DIMCA는 비교 대상(GCN, MLP) 대비 임무 성공률을 일관되게 상향 유지했으며, 시간 경과에 따라 재할당 반응성을 통해 임무 실패 위험을 선제적으로 대응하고, 이동·연료소모를 줄여 자원 활용 효율을 개선하였다. 따라서 본 연구는 다영역 전장의 OODA(Object-Orient-Decide-Act) 루프 가속과 작전 복원력 향상에 기여할 수 있음을 보여준다. 키워드: 유·무인 복합체계, 지휘통제, 인공지능, 임무 재할당, 협업 Ⅰ. 서 론현대 전장은 지상·해양·공중·사이버·우주 등 다영역 작전의 증가로 인해 복잡성·속도 등의 측면에서 빠르게 진화하고 있으며, 미래 전장에서는 더욱 심화할 것으로 예상된다. 이에 따라 전통적인 인간 중심의 전쟁 방식에서 첨단 기술을 적용한 최첨단 무기체계로의 전환이 요구되고 있다. 러시아-우크라이나전, 이스라엘-하마스전에서 볼 수 있듯이 드론·로봇 등 무인 전투체계는 작전 수행에 필수적인 요소로 주목받고 있다. 따라서, 인간 전투요원과 무인 무기체계가 협업하는 유·무인 복합전투체계는 OODA 루프를 가속화하고 효과적인 작전 수행 능력을 향상시키는 혁신적인 군사 플랫폼으로 인식되어 세계 주요 국방 선진국들은 MUMT의 도입을 촉진하기 위한 정책 수립과 핵심기술 확보에 역량을 집중하고 있다. MUMT는 기존 전력의 단순한 증강을 넘어 복잡한 전장에서 향상된 능력과 운용 효율성으로 작전 개념을 근본적으로 변화시킨다. 예를 들어, 드론과 같은 소형 무인 항공 시스템은 저렴한 획득 및 운용 비용으로 운용이 가능하며 위험한 정찰 및 타격 임무를 수행함으로써 인간 전투원의 손실 위험을 줄이는 데 효과적이다. 역동적이고 예측 불가능한 전장 환경에서는 무기체계의 손상, 새로운 위협의 출현, 임무 목표 변경과 같은 예상치 못한 상황이 필연적으로 발생한다. 무인체계가 사전 계획된 임무로 이런 급격한 변화에 대처하는 것은 매우 어렵다. 따라서 무인체계가 실시간으로 임무를 조정하고 동적으로 재계획할 수 있는 능력은 작전 효율성을 유지하고 시스템 복원력을 보장하는 데 매우 중요하다. 따라서 무인체계에 인공지능 기술을 적용하는 것은 이런 제한사항을 완화 또는 제거하기 위한 필수적인 방법이다. 인공지능 기술을 통해 자율 항법, 동적 장애물 회피, 최적 경로 계획 등 전장 환경 변화에 따른 다양한 임무를 수행할 수 있다. 그러나, 다수·다종의 무인체계 간의 공동 목표 할당, 분산 탐색, 임무 달성을 위한 조정된 행동 등의 효과적인 협업을 위해서는 적응형 자율성이 필요하며, 이를 구현하기 위한 정교한 알고리즘이 필요하다. 따라서, 본 연구는 MUMT 내에서 AI 기반 동적 임무 재할당 및 협업 운영을 위한 혁신적인 알고리즘을 제안한다. 이를위해 예측 불가능한 상황에 대한 실시간 적응 프레임워크를 설계하고, 다중 플랫폼 간 협업 및 체계 복원력 향상을 위한 알고리즘을 연구한다. 본 논문의 구성을 다음과 같다. 제2장은 관련연구를 통해 기존의 연구내용과 한계를 분석한다. 제3장과 제4장은 유·무인 복합전투체계의 임무 재할당 및 협업 아키텍처를 제안한다. 제5장은 시뮬레이션을 통해 제안된 아키텍처의 유효성을 검증한다. 제6장은 연구결과를 요약하고 향후 연구방향에 대해 제시한다. Ⅱ. 관련연구MUMT는 미래 전장에서 전투 효율성과 생존성을 높이는 핵심 자산이다. MUMT의 효과적 운용을 위해서는 수시로 변화하는 동적 임무 환경에 대응할 수 있도록 실시간 임무 재할당, 이기종 플랫폼 간의 지능형 협업 전략이 필수적이다. 이에 따라 다중 에이전트 강화 학습(MARL: Multi-Agent Reinforcement Learning), 그래프 기반 협업 모델, 분산 최적화 등의 기술을 활용한 다양한 연구가 진행되고 있다. Jin et al.은 다중 에이전트 협업 의사결정 기법에 대한 다양한 방법론을 조사하였으며 특히 MARL과 LLM(Large Language Model) 기반의 기법에 대해 초점을 맞추어 분석하였다[1]. 그러나 논문에서 제시한 기법들은 전장 환경의 도전적 과제(예상치 못한 위협 발생, 플랫폼 손상, 새로운 임무 부여 등)에 대한 해법을 구체적으로 제시하고 있지 않다. Ratnabala et al.은 이기종 다중 에이전트 시스템에서 효율적인 분산형 임무 할당 문제를 해결하기 위해 MAGNNET를 제안하였다[2]. 중앙집중 학습 및 분산 실행 기반의 프레임워크에 PPO(Proximal Policy Optimization)와 GNN(Graph Neural Network)을 통합하여 무인 항공기와 및 무인 지상차량 등의 동적 임무 할당을 제시하였다.최대 20개 에이전트 규모까지 확장성 있게 동작하며, 동적 과업 생성에도 실시간 대응이 가능함을 보여주었다. 그러나, 그리드 기반의 단순 환경에 적용하여 복잡한 전장 시나리오를 적용하기에는 한계가 있다. Goeckner et al.은 에이전트의 손실, 통신 장애 등의 상황에서도 분산 협업이 가능한 MAGEC 프레임워크를 제안한다[3]. MARL과 GNN을 통합하여 장애 상황에서도 성능의 저하없이 임무를 수행하였으나, 순찰 시나리오 중심으로 검증되어 실제 작전 임무(정찰,공격,방어 등)의 복합 전장 환경에는 적용이 제한적이다. Zhao et al.은 이기종 에이전트의 구조화된 정보를 융합하고 각 에이전트의 의사결정 정확도를 높이는 방법을 제안하였으나 이 방법도 실질적인 전술적 운용에 적용하기는 어렵다[4]. Yu et al.은 다중 에이전트 테스트환경에서 좋은 성능을 보이는 다중 에이전트 근접 정책 최적화(MAPPO) 알고리즘을 제안했고[5], Liao et al. MAPPO 기반의 다중 무인기 탈출 표적 탐색 알고리즘을 제안하였다[6]. 그러나 이 알고리즘들은 목표 탐색 중심으로 플랫폼 간 협업이나 다양한 임무 유형 대한 적용은 부족하였다. Hunt et al.은 인간과 군집 로봇의 상호작용을 하고, 인간의 제어를 통해 군집 로봇이 임무를 수행하는 시뮬레이터를 개발하였으나, 군사 임무 조건이나 적 위협 등의 전장 조건이 포함되지 않은 한계가 있다[7]. Selmonaj et al.은 MARL을 전술 AI 개발에 적용하여 의사결정 프로세스를 개선하는데 초점을 두고 있다[8]. 그러나 이 논문은 주어진 임무 내에서 의사결정에 중점을 두고, 임무 자체를 변경하는 임무 재할당 등에 대해서는 충분히 고려하지 않고 있다. Li et al.은 복잡한 시나리오에서 실시간 동적 장애물을 회피하는 심층강화학습 모델을 제안한다[9]. 민간 환경에서 알려져 있거나 예측가능한 장애물(보행자, 다른 차량 등)을 피하는 시나리오에 강점을 보이고 있으나, 전장환경에서 고려할 수 있는 다양한 위협에 따라 회피 전략을 어떻게 변경하거나 임무를 재계획할 것인지에 대해 명시적으로 제시하고 있지 않다. Liu et al.은 실시간 다중 무인 항공기 협업 임무계획 알고리즘을 제안한다[10]. 외부 환경의 급격한 변화(플랫폼 손실 등)가 발생할 때, 실시간 임무 재계획을 보장하지만, 이기종 플랫폼에 대한 검증이 필요하다. 따라서 본 논문은 동적인 전장환경에서 이기종의 무인체계와 인간이 협업하여 임무를 효과적으로 수행할 수 있는 알고리즘을 제시한다. Ⅲ. AI 기반 동적 임무 재할당 및 협업 아키텍처본 논문에서는 인간 지휘관/전투원,공중·지상 무인체계가 참여하는 유·무인 복합전투체계를 대상으로 AI 기반 동적 임무 재할당 및 협업 시스템으로써 DIMCA(Dynamic Intelligent Mission and Collaboration Architecture)를 제안한다. 이 시스템은 실시간 전장 상황을 인식하고 강화학습 기반의 의사결정을 통해 최적의 임무 재할당을 수행하며, 그래프 기반의 협업 전략을 통해 이기종 에이전트 간의 시너지를 극대화하는 것을 목표로 한다. DIMCA는 유·무인 복합전투체계의 다양한 에이전트와 모듈화된 알고리즘 구조를 통해 복잡한 전장 환경에 유연하게 대응하도록 제안한다. 3.1 에이전트 구성본 시스템은 유인 에이전트, 공중 무인 에이전트, 지상 무인 에이전트 등 세 가지 유형의 에이전트로 구성되며, 각 에이전트는 고유한 역할을 가진다. 먼저, 유인 에이전트는 인간 지휘관 또는 전투원으로서 전략적 판단, 법·윤리적 사항 확인, 최종임무 승인 및 감독 임무를 수행한다. 무인체계가 제안하는 복잡한 동적 임무 재할당 결정에 대해 설명가능한 정보를 제공받아, 인간의 인지 부하를 줄이면서도 적시 적절한 통제를 유지한다. 공중 무인 에이전트는 광범위한 감시 및 정찰 수행, 신속한 표적 타격 등 높은 기동성을 요구하는 임무를 수행한다. 한된 체공 시간과 탑재 중량 내에서 최대의 효율을 발휘하도록 역할이 부여된다. 지상 무인 에이전트는 지상 정찰, 표적 추적, 표적 타격 및 지역 확보 등 견고함과 지속성을 요구하는 임무를 수행한다. 다양한 지형에서 안정적인 운용이 가능하며, 공중 무인 에이전트 대비 장시간 임무 수행 능력을 갖춘다. 3.2 임무 모델시스템이 수행하는 임무는 유형, 중요도, 위치, 소요 시간, 요구 자산 등의 속성을 가지며, 이 속성들은 동적 임무 재할당의 기준이 된다. 임무 유형은 정찰, 타격, 지역 확보 등의 다양한 작전 유형을 포함한다. 중요도는 각 임무의 전술적 중요도(예: 최우선, 고, 중, 저)를 나타내며, 재할당 시 우선순위를 결정할 때 사용된다. 위치는 임무가 수행될 지리적 좌표를 포함하여, 에이전트의 이동 경로 및 도달 가능성을 계산하는 데 활용된다. 소요 시간은 임무 완료에 필요한 예상 시간을 나타내며, 에이전트의 가용성 및 자원 배분을 계획할 때 중요한 요소로 활용한다. 요구 자산은 임무 수행에 필요한 특정 에이전트 유형(예: 공중, 지상, 인간 감독), 무장, 통신 범위 등의 필수적인 능력들을 명시한다. 3.3 시스템 구조제안하는 DIMCA는 전장의 불확실성과 동적 상황 변화에 대응하기 위해 인식모듈, 결심모듈, 협업 모듈 등 세 가지 핵심 모듈로 구성되어, 실시간 전장 상황인식부터 최적의 의사결정 및 협업 전략 수립까지의 과정을 유기적으로 연결한다. 인식 모듈은 다양한 EO/IR, 레이더, 음향 등 다양한 외부 센서로부터 수집되는 실시간 전장 정보를 통합하고 융합한다. 융합된 데이터를 기반으로 새로운 위협의 감지 및 분류, 아군 플랫폼의 손상 정도 평가, 환경 변화(예: 지형 변화, 기상 악화) 등 예상치 못한 상황을 실시간으로 식별한다. 결정 모듈은 강화학습 기반의 상태-행동 정책을 통해 각 에이전트의 개별 행동(예: 경로 계획, 표적 추적)을 결정하며, 임무 성공률, 자원 효율성, 생존율 등의 다양한 요소를 반영한 다목적 보상함수를 기반으로 정책을 최적화한다. 에이전트의 상태 변화에 따라 기대 성공 확률을 실시간으로 평가하고, 성공 확률이 임계값 이하로 하락하면 임무를 재할당한다. 협업 모듈은 모든 에이전트(유인, 무인)와 현재 활성화된 임무들을 정점(Node)으로 하는 동적인 그래프를 구성한다. 간선(Edge)은 에이전트 간의 통신 링크, 시야 확보 여부, 근접성, 공유된 목표, 지휘 계통 등 다양한 관계를 나타낸다. 그래프 어텐션 네트워크(Graph Attention Network, GAT)를 활용하여 각 노드(에이전트 또는 임무)의 중요도와 상호 관계를 학습하고, 에이전트의 현재 상태(건강상태, 자원, 위치), 능력, 요구 자산에 따라 동적으로 변화한다. 학습된 관계를 바탕으로 주어진임무에대해 최적의 협업조합을생성한다. 이는 특정 임무에 가장 적합한 유·무인 에이전트 팀을 구성하고, 각 에이전트에게 할당될 역할을 제안하는 것을 포함한다. 협업 모듈은 모든 에이전트(유인, 무인)와 현재 활성화된 임무들을 정점(Node)으로 하는 동적인 그래프를 구성한다. 간선(Edge)은 에이전트 간의 통신 링크, 시야 확보 여부, 근접성, 공유된 목표, 지휘 계통 등 다양한 관계를 나타낸다. 그래프 어텐션 네트워크(Graph Attention Network, GAT)를 활용하여 각 노드(에이전트 또는 임무)의 중요도와 상호 관계를 학습하고, 에이전트의 현재 상태(건강상태, 자원, 위치), 능력, 요구 자산에 따라 동적으로 변화한다. 학습된 관계를 바탕으로 주어진 임무에 대해 최적의 협업 조합을 생성한다. 이는 특정 임무에 가장 적합한 유·무인 에이전트 팀을 구성하고, 각 에이전트에게 할당될 역할을 제안하는 것을 포함한다. 제안하는 시스템은 하이브리드 계층구조를 채택한다. 모든 에이전트는 세 가지 공통 모듈을 보유하되, 기능 수준과 결정 권한은 계층에 따라 차별화된다. 중앙 통제자(예: 인간 지휘관)는 전체 상황 통합과 전역 임무 재할당을 담당하며, 전술 에이전트(예: UAV, UGV 등의 무인체계)는 로컬 수준에서의 행동 계획, 위험 회피, 근거리 협업 등을 수행한다. 중앙 통제자는 설명가능한 판단 근거를 제공받아 최종 결정 권한을 행사함으로써 시스템의 신뢰성과 책임성을 확보한다. 이러한 구조는 중앙집중형 전략 판단과 개별 에이전트의 자율적 판단을 유기적으로 결합함으로써, 통신 제한 상황에서도 탄력적인 작전 수행을 가능하게 하며, 전장 복잡도에 대한 적응성과 복원력을 동시에 확보할 수 있도록 설계되었다. 그림 1은 하이브리드 시스템 아키텍처를 나타낸 것이다. Ⅳ. DIMCA 설계4.1 에이전트 구성제안하는 시스템은 유·무인 복합전투체계 내의 다수 에이전트가 부분 정보를 기반으로 상호작용하는 환경을 모델링하기 위해, 단일 에이전트 강화학습 모델인 부분 관측 마르코프 결정 과정(POMDP: Partially Observable Markov Decision Process)을 다중 에이전트 환경으로 확장한 부분 관측 마르코프 게임(POMG: Partially Observable Markov Game)을 기반으로 설계한다. POMDP는 하나의 에이전트가 불완전한 정보를 바탕으로 최적의 정책을 학습하는 데 초점을 맞추며, POMG는 이를 여러 에이전트가 각자의 제한된 관측을 바탕으로 상호작용하는 복합 구조로 일반화한 것이다. 본 문제는 다수의 에이전트가 부분적인 정보를 가지고 상호작용하며 공동의 목표를 달성하는 부분 관측 마르코프 게임으로 정의된다. 각 에이전트 i는 시각 t에서 전장 상황의 일부만을 관측할 수 있으며, 다른 에이전트의 행동과 환경 변화에 따라 자기 행동을 결정한다. 본 연구에서 사용하는 상태, 행동, 보상은 다음과 같이 정의한다. 먼저, 에이전트 i의 상태 벡터 si,t는 식(1)과 같이 구성된다.
여기서, pi,t는 에이전트 위치, vi,t는 속도, ri,t는 연료 상태, mi,t는 임무 유형, ci,t는 통신 상태, di,t는 적 탐지 거리를 의미한다. 이와 같은 상태 정의를 통해 에이전트는 다음과 같은 행동을 선택할 수 있다. 에이전트는 이산적인 행동공간 ai,t ∈ Ai 을 가지며, 는 식(2)과 같이 구성된다.
여기서, Move는 기동 행동, Engage는 교전 행동, Scan은 정보를 수집하는 감지 행동, Relay는 아군에게 정보를 전파하는 통신 행동에 해당한다.
(3)[TeX:] $$R_t=\omega_1 \cdot R_{\text {mission }}+\omega_2 \cdot R_{\text {safety }}-\omega_3 \cdot R_{\text {cost }}$$여기서, Rmission은 임무성공 시 보상, Rsafety는 에이전트 생존 시 보상, Rcost는 이동거리 및 연료 소모에 비례한 패널티를 의미하며, w1,w2,w3는 각 항목의 중요도를 조절하기 위한 가중치이다. 알고리즘의 최종 목적은 모든 에이전트의 공동 정책 (π)을 최적화하여, 시간에 따른 총 기대 보상을 최대화하는 것으로 식(4)과 같이 표현된다.
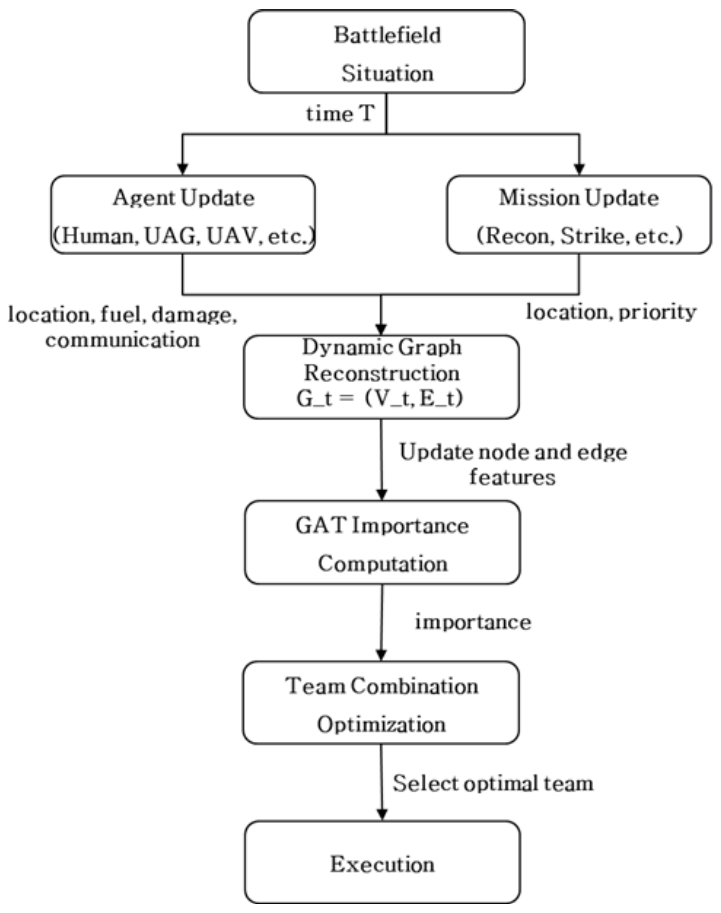
여기서, π는 모든 에이전트가 각 상태에서 취해야 할 공동 정책을 나타내고, E는 기대값을 의미한다. γ는 강화학습 할인율로 미래의 보상에 대한 현재의 가치를 (0 < γ < 1)의 범위에서 조절한다. Rt는 시점 t의 보상을 나타내며, 임무 성공·자원 효율성·에이전트 생존 여부 등의 다양한 요소를 포함한다. T는 임무 수행의 전체 시간 단계를 말한다. 4.2 동적 임무 재할당동적 임무 재할당 알고리즘은 실시간 전장 변화에 적응하기 위한 DIMCA의 핵심 알고리즘으로, 예기치 못한 상황 발생 시 유연하고 신속한 대응을 가능하게 한다. DIMCA의 동적 임무 재할당 알고리즘은 여섯 단계로 구성된다. 첫째, 모든 유인 및 무인 에이전트는 인식 모듈을 통해 자신과 주변의 상태를 지속적으로 감지하고 전파한다. 여기에는 자신의 위치, 속도, 자원 상태(연료, 배터리 등), 무장 및 통신 상태, 손상 여부 등이 포함되며, 동시에 현재 수행 중인 임무 리스트와 전체 임무 상황도 함께 업데이트된다. 둘째, 결정 모듈은 최신 전장 정보와 에이전트 상태, 임무의 요구 역량을 바탕으로 각 임무의 기대 성공 확률을 실시간으로 계산한다. 이때, 손상 모델이나 자원 소모 모델 등 사전 학습된 요소가 함께 고려되어, 임무 실패 가능성을 정량적으로 평가한다. 셋째, 만약 특정 임무의 성공 확률이 임계값 이하로 떨어지거나, 새로운 최우선 임무가 등장할 경우, 임무 재할당 알고리즘이 동작한다. 이때, 기존 임무는 보류되거나 취소되며, 가용 자원을 재조정하여 신속하게 대응한다. 넷째, 협업 모듈이 활성화되어 현재 전장 상황과 임무 특성을 기반으로 가능한 팀 조합을 탐색한다. 이 모듈은 그래프 기반 구조를 사용하여 유·무인 에이전트 및 임무 간 관계를 동적으로 분석하고, 최적의 협업 후보를 도출한다. 다섯째, 그래프 어텐션 네트워크(GAT)를 활용하여 후보팀 조합 중 가장 효율적이고 성공 확률이 높은 조합을 선택한다. 이 과정은 에이전트의 능력, 현재 상태, 임무와의 적합성 등을 종합적으로 고려한다. 마지막으로, 인간 지휘관에게 설명가능한 판단 근거와 함께 새로운 팀 조합을 제시하고, 지휘관의 승인 또는 조정을 거쳐 최종 임무 재할당을 실행한다. 이러한 인간-중심의 개입은 책임성과 윤리적 판단을 보완하며, 자동화 편향을 줄이는 데 기여한다. 제안하는 알고리즘은 아래와 같이 정리할 수 있다. 4.3 그래프 기반 협업 전략그래프 기반 협업 전략은 이기종 유·무인 에이전트 간의 협업 관계를 전장 환경과 임무 상황 변화에 따라 실시간으로 재구성하는 동적 모델링 기법을 제안한다. 이를 통해 최적의 임무 수행 조합을 실시간으로 도출한다. 이 전략은 단순히 정적 그래프에서 GAT를 학습하는 기존 접근방식과 달리, 시간 t마다 재구성되는 동적 그래프를 기반으로 하여 전장 환경의 급격한 변화와 에이전트의 상태 변화를 모두 고려하여 협업 구조를 유연하게 재구성한다. DIMCA의 신경망 구조는 세 단계로 구성된다. 입력 단계는 에이전트의 상태를 특징 벡터로 변환하여 노드 표현으로 인코딩한다. 특징 추출 단계에는 두 개의 GAT 계층을 통해 노드 간 관계 정보를 임베딩한다. 출력 단계에는 GAT 계층의 결과를 기반으로 각 행동을 산출한다. 이를 제안하는 시스템에 적용하면 다음과 같다. 먼저, 모든 유인 에이전트, 공중 무인 에이전트(UAV), 지상 무인 에이전트(UGV), 그리고 활성화된 임무들을 노드로 구성한 동적 그래프를 생성한다. 간선은 통신 가능성, 물리적 거리, 시야 확보 상태, 동일 목표 여부 등 다양한 관계적 특성을 반영하여 구성되며, 상황 변화에 따라 주기적으로 갱신된다. GAT는 각 노드의 속성(예: 에이전트의 능력, 현재 상태, 임무의 중요도)과 주변 노드와의 관계를 고려하여, 특정 임무 맥락에서 해당 노드가 얼마나 중요한 역할을 할 수 있는지를 학습한다. 예를 들어, 특정 지역에 새로운 위협이 발생하면, 해당 지역에 가장 가까운 UAV와 UGV 및 그들을 지휘할 수 있는 인간 지휘관의 중요도가 높아진다. 학습된 GAT의 출력은 단일 노드 중요도 산출에 그치지 않고, POMG 기반의 다목적 보상 함수를 결합하여 임무-에이전트 간 배치 최적화를 수행한다. 이 과정에서 자원 제약, 거리·통신 조건, 에이전트 간 시너지 계수 등 다중 제약조건을 종합적으로 반영한다. 협업 모듈은 이를 바탕으로 현재 임무 수행에 가장 적합한 에이전트 조합을 도출하며, 필요시 중앙 통제자가 승인·조정하는 하이브리드 의사결정 구조를 유지한다. GAT 기반 협업 전략의 절차는 그림 2과 같다. Ⅴ. 실험 및 검증본 연구에서 DIMCA의 POMG 기반 동적 임무 재할당 및 협업 알고리즘 유효성을 검증하기 위해 시뮬레이션을 수행하였다. 제안하는 알고리즘과 기존의 그래프 기반 기법인 GCN(Graph Convolutional Network) 및 MLP(Multi-Layer Perceptron)와 비교 분석하였다. 다영역 작전 상황을 고려하여 유·무인 복합전투체계 운용 시나리오를 다음과 같이 정의하였다. 임무 유형은 Recon(정찰), Attack(타격), Occupation(지역 확보)의 세 가지로 구성된다. Recon 임무는 지정된 목표 지역에 접근하여 일정 시간 이상 감시·정찰을 수행하면 임무 성공으로 판단한다. Attack 임무는 탐지·식별된 적 위협에 대해 사거리에 접근하면 타격을 수행하고, 아군 에이전트가 생존할 경우 성공으로 간주한다. Occupation 임무는 특정 지역을 점유하고 일정 시간(예: 10분 이상)이상 점유를 유지하는 경우 임무 성공으로 정의한다. 새로운 임무는 사전에 할당되지 않은 긴급 임무를 말하며 무작위 위치에서 발생하고 현재 부여된 임무보다 우선하는 임무를 말한다.새로운 임무는 일정 시간 간격(평균 10 Hour 마다 확률 0.3)으로 발생하며, 주로 Attack 및 Occupation 유형의 고우선순위 임무가 새롭게 생성되는 상황을 가정한다. 에이전트 손상 이벤트는 평균 50 Hour마다 확률 0.3으로 발생하여 UAV 또는 UGV의 기동성 저하, 센서 기능 상실,통신 모듈 손상 등의 형태로 모델링된다. 이때 해당 에이전트에 할당된 임무의 성공 확률은 급격히 감소하며, DIMCA의 동적 임무 재할당 알고리즘이 활성화된다. 또한 통신 저하 상황은 에이전트 간 유효 통신 거리 감소 또는 일시적인 링크 단절로 구현하여, 협업 구조 및 팀 구성의 변화를 유도하였다. 이와 같이 정의된 임무 시나리오를 통해 제안하는 DIMCA가 정적 환경뿐 아니라 새 임무 생성, 플랫폼 손상,통신 제약 등 전형적인 전장 동적 이벤트에 대해 얼마나 신속하고 효율적으로 적응하는지를 정량적으로 평가할 수 있도록 하였다. 시뮬레이션은 200 Hours 동안 20회 반복 수행되었으며, 시간 경과에 따른 동적 성능 변화를 중점적으로 평가하였다. 시뮬레이션 주요 파라미터는 표 1과 같다. 표 1. Simulation Parameter
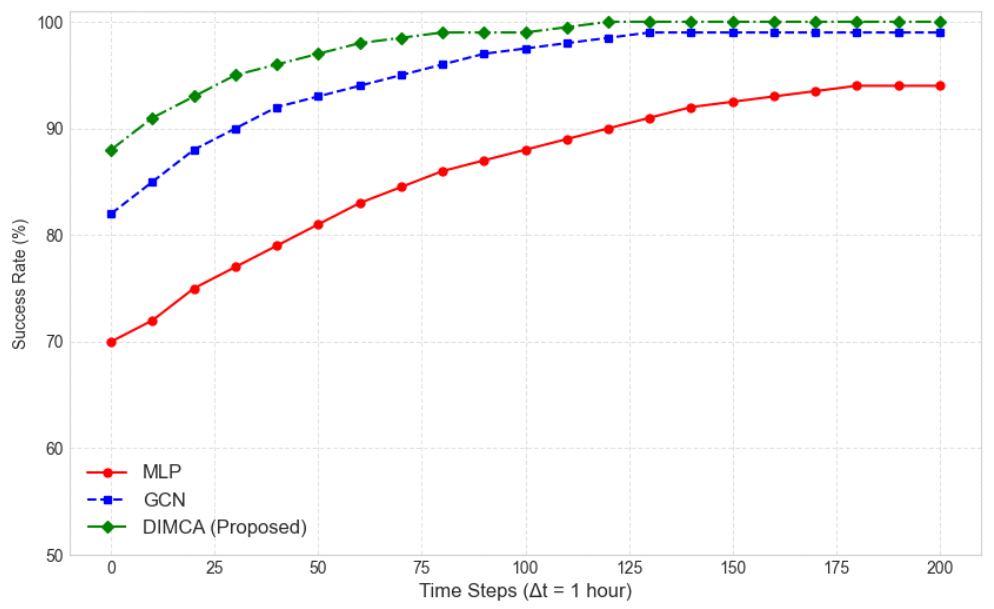
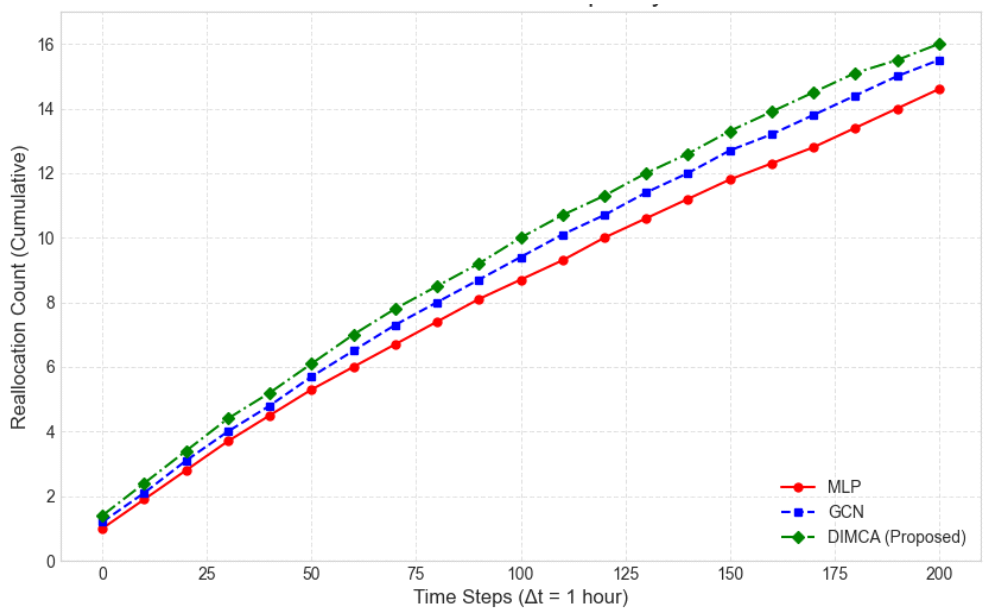
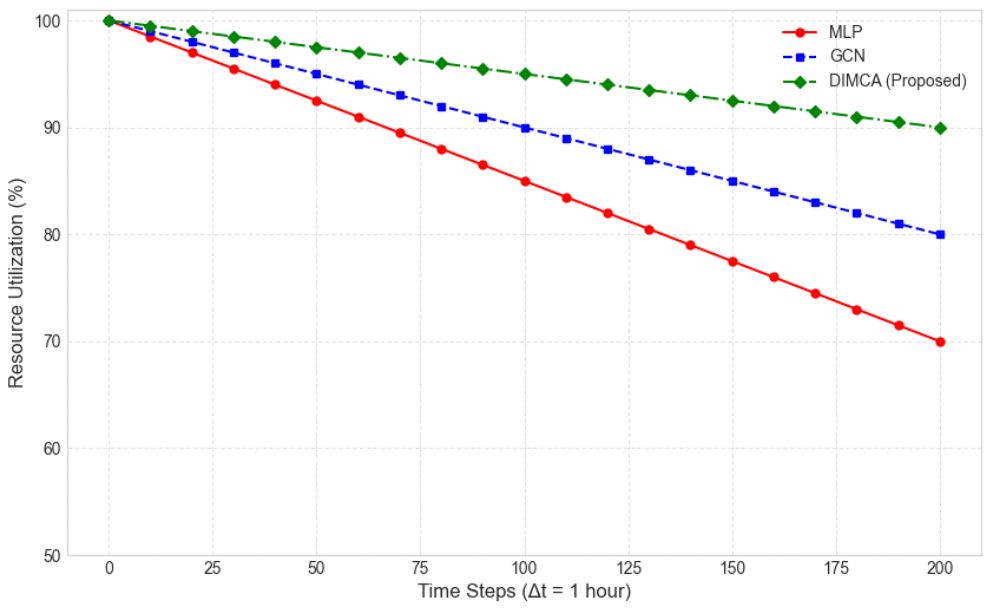
본 연구의 시뮬레이션은 유·무인 복합 전투체계 환경 하에서 동적 환경에 대한 알고리즘의 강건성과 운영적 안정성을 평할 수 있는 세 가지 핵심 메트릭을 선정하여 평가하였다. 그림 3은 임무성공률을 나타낸다. 임무성공률은 생성된 총 임무에 대해 완료된 임무의 비율을 나타내는 것으로 동적 환경에서 최종 목표를 얼마나 잘 달성하는 지를 확인할 수 있다. 결과를 분석해 보면 DIMCA는 시뮬레이션 전반에 걸쳐 가장 높은 성공률을 유지했으며, 특히 120 Hour 이후부터는 100%에 근접하는 성공률을 기록하며 압도적인 신뢰성을 보였다. 이는 DIMCA가 GAT의 어텐션 메커니즘을 통해 동적 이벤트 발생 시 가장 적합하고 역량이 충분한 에이전트에게 즉각적으로 임무를 재할당했기 때문이다. GCN은 이웃 정보를 활용함에도 불구하고 DIMCA에 비해 약 3∼5% 낮은 성공률을 보였다. 이는 GCN이 모든 이웃에게 균등한 가중치를 부여하여 최적의 결정을 놓쳤기 때문으로 분석된다. MLP는 가장 낮은 성공률에 머물렀는데 주변 에이전트의 상태나 임무를 고려하지 않고 비효율적인 할당을 반복했기 때문이다. 그림 4는 누적 임무 재할당 빈도를 나타내는 것이다. 동적 이벤트(새로운 임무 부여 또는 팀 에이전트의 손상 등)로 인해 임무를 재할당하는 적응성을 확인해 볼 수 있다. DIMCA는 시간이 지남에 따라 GCN, MLP보다 가장 높은 누적 재할당 빈도를 보였다. 이는 DIMCA가 시스템의 안정성을 유지하기 위해 적극적으로 개입했음을 나타낸다. 동적 이벤트(매 10Hours, 50Hours)가 발생할 때마다 세 모델 모두 재할당 횟수가 증가했지만, DIMCA는 다른 모델들보다 더 작은 규모의 변화에도 재조정을 수행하여,위험을 사전에 차단하는 적응성이 뛰어남을 보여준다. 그림 5는 자원 활용률을 나타내는 것으로 시스템의 운영 효율성을 측정할 수 있다. DIMCA는 시뮬레이션 전반에 걸쳐 가장 높은 자원 활용률(최저 연료 소모)을 유지했는데 이는 에이전트의 잔여 자원 상태를 의사결정 요소에 포함하여 자원 낭비를 최소화했기 때문이다. MLP는 가장 낮은 자원 활용률을 보였다. 이는 비효율적인 할당으로 인해 에이전트들이 불필요하게 먼 거리를 이동하거나, 임무 수행에 적합하지 않은 에이전트가 낭비되는 경우가 잦았음을 의미한다. 따라서 제안하는 DIMCA는 동적 환경이 빈번하게 변화하는 유·무인 복합전투체계 환경에서 최적의 팀을 구성하여 임무를 수행하고, 신뢰성·적응성·자원 효율성 측면에서 효과적인 방안이라는 것을 증명하고 있다. Ⅵ. 결 론본 연구는 유·무인 복합전투체계 환경에서 발생할 수 있는 동적 임무 재할당 및 협업 문제를 해결하기 위해 DIMCA 아키텍처를 제안하였다. 제안된 DIMCA는 유·무인 에이전트 간의 동적 관계와 임무 특성에 따른 중요도를 실시간으로 측정하여 최적의 팀 구성과 임무 수행에 초점을 맞추었다. 시뮬레이션 및 비교 분석을 통해 제안된 DIMCA는 비교 기법(GCN, MLP) 대비 임무 성공, 임무 재할당, 자원 소모 등에서 상당한 개선이 있음을 확인하였다. DIMCA는 소규모 변화에도 선제적으로 개입해 임무 실패 위험을 낮추는 경향을 보였고, 거리·통신·잔여 자원을 동시 고려한 팀 배정으로 이동 및 연료 소모를 절감하는 효과를 달성하였다. 이는 동적인 전장환경에서 효율적인 자원 배분과 효과적인 작전 임무 수행이라는 두 가지 측면을 동시에 달성할 수 있음을 의미한다. 본 연구는 DIMCA의 유효성을 검증하는 데 성공하였으나, 대규모 군집으로 확장된 복잡한 상황에서 실시간 성능, GPS 교란 또는 통신 교란 환경에서 강건한 작동, AI 결정의 신뢰성 및 설명가능성 보장에 대한 기술적 도전과제가 남아있다. 또한 실제 MUMT 체계 적용에 있어 적대적·다영역 혼합현실 환경에서의 추가 검증, 분산 추론·모델 경량화·메시지 우선 순위화에 의한 실시간성 확보 등이 필요하며 향후 연구를 통해 보완해 나갈 예정이다. BiographyReferences
|
StatisticsCite this articleIEEE StyleJ. Cho, "A study on AI-based dynamic intelligent mission and collaboration architecture for MUMT," The Journal of Korean Institute of Communications and Information Sciences, vol. 51, no. 1, pp. 223-231, 2026. DOI: 10.7840/kics.2026.51.1.223.
ACM Style Jaekyu Cho. 2026. A study on AI-based dynamic intelligent mission and collaboration architecture for MUMT. The Journal of Korean Institute of Communications and Information Sciences, 51, 1, (2026), 223-231. DOI: 10.7840/kics.2026.51.1.223.
KICS Style Jaekyu Cho, "A study on AI-based dynamic intelligent mission and collaboration architecture for MUMT," The Journal of Korean Institute of Communications and Information Sciences, vol. 51, no. 1, pp. 223-231, 1. 2026. (https://doi.org/10.7840/kics.2026.51.1.223)
|